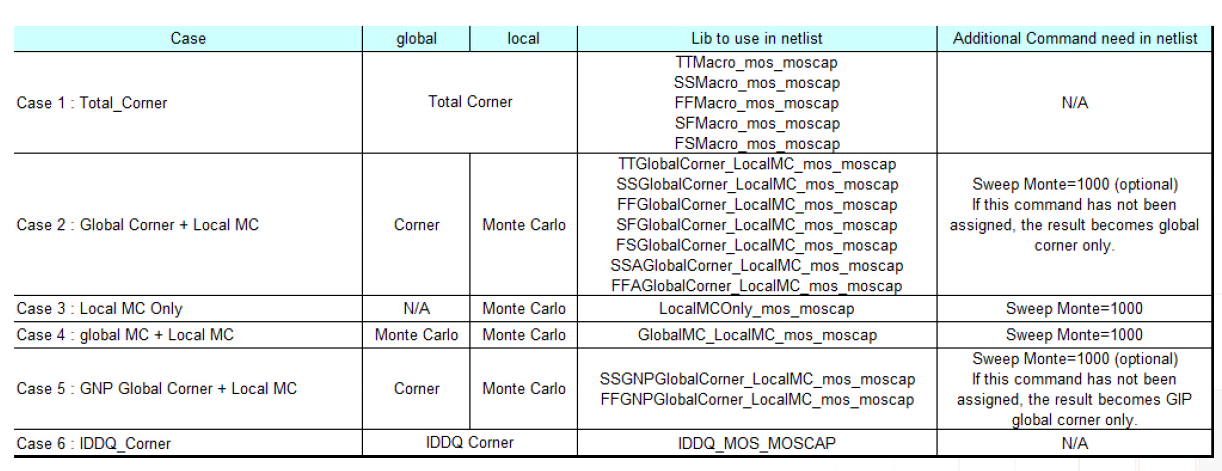
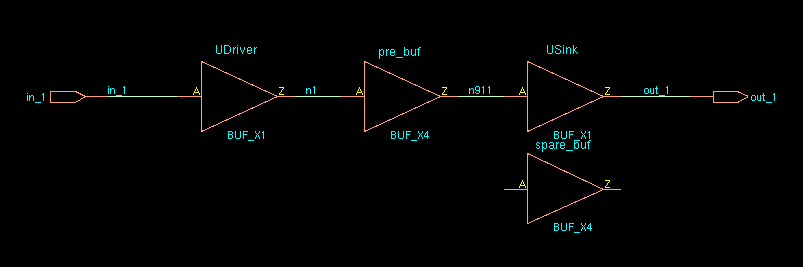
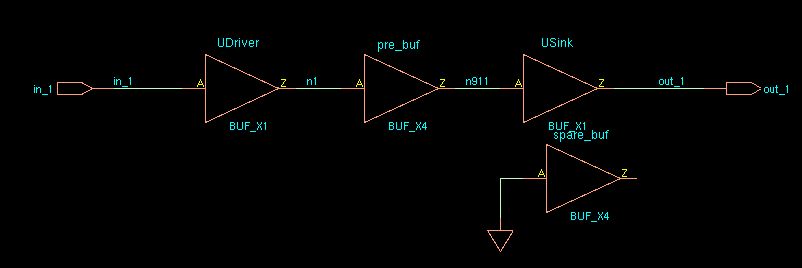
Local Monte-Carlo (SSG, FFG with Local Gaussian) as
Signoff golden
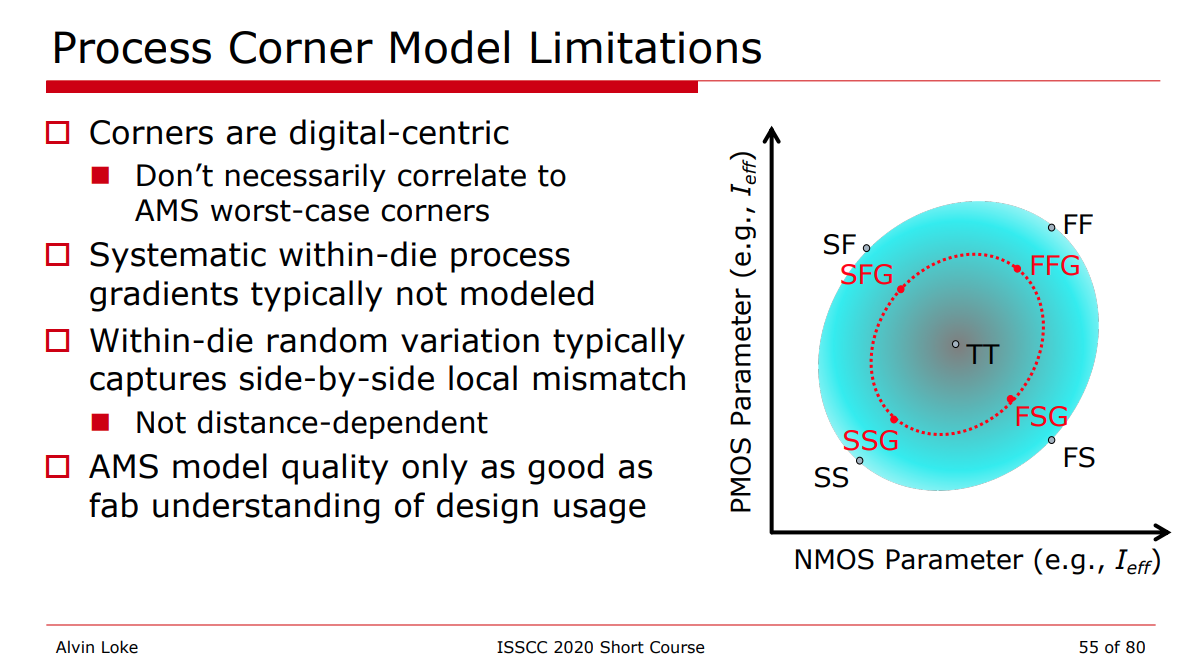
Process Corner Model
Limitations
Variation section
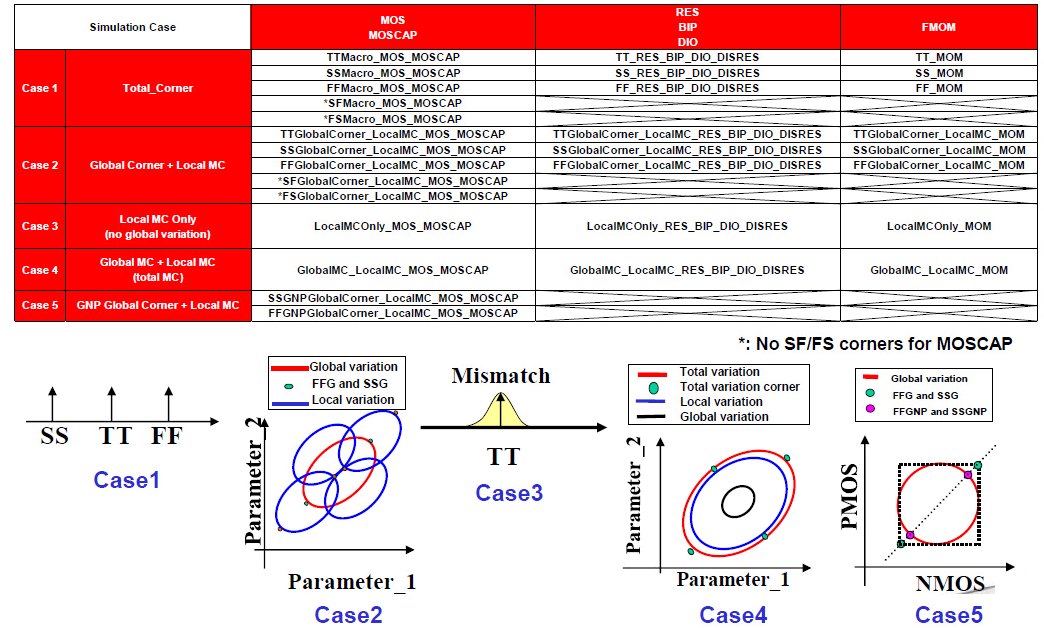
Total corner (TT/SS/FF/SF/FS)
E.g. TTMacro_MOS_MOS_MOSCAP
Global Corner (TTG/SSG/FFG/SFG/FSG) + Local MC
E.g. TTGlobalCorner_LocalMC_MOS_MOSCAP
Local MC
E.g. LocalMCOnly_MOS_MOSCAP
Global MC + Local MC (Total MC)
GlobalMC_LocalMC_MOS_MOSCAP
SSGNP, FFGNP:
When N/P global correlation is weak (R^2=0.15), the corner of N/PMOS
balance circuit (e.g. inverter) can be tightened (3sigma ->
2.5sgma) due to the cancellation between NMOS
and PMOS
SSGNP, FFGNP usually used in Digital STA
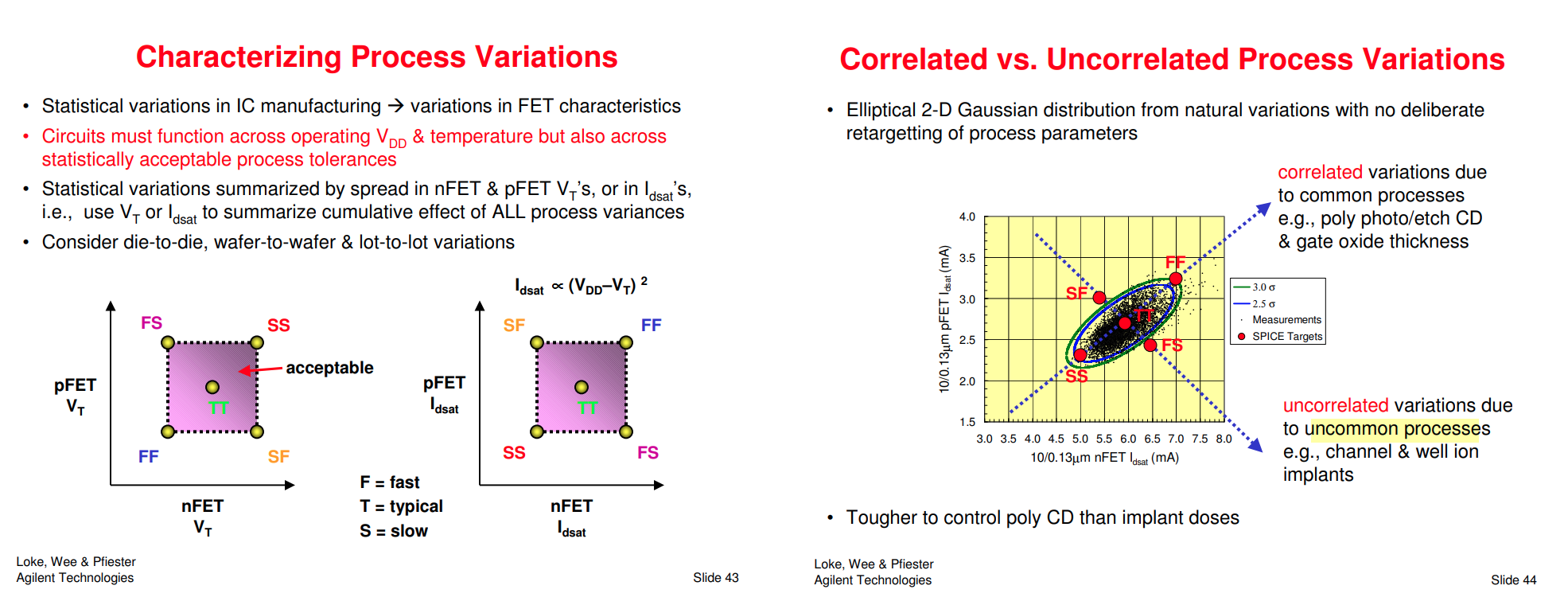
Global variation validation with global
corner
3-sigma of global MC simulation is aligned with
global corner
Total variation validation with total
corner
3-sigma of global MC + local MC (total) simulation
is aligned with total corner
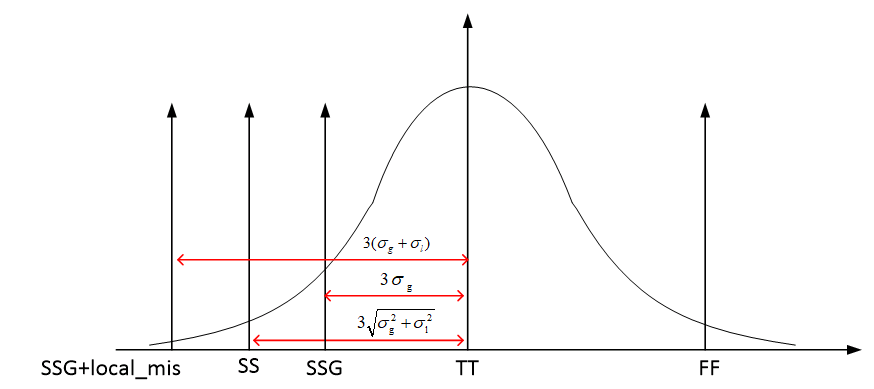
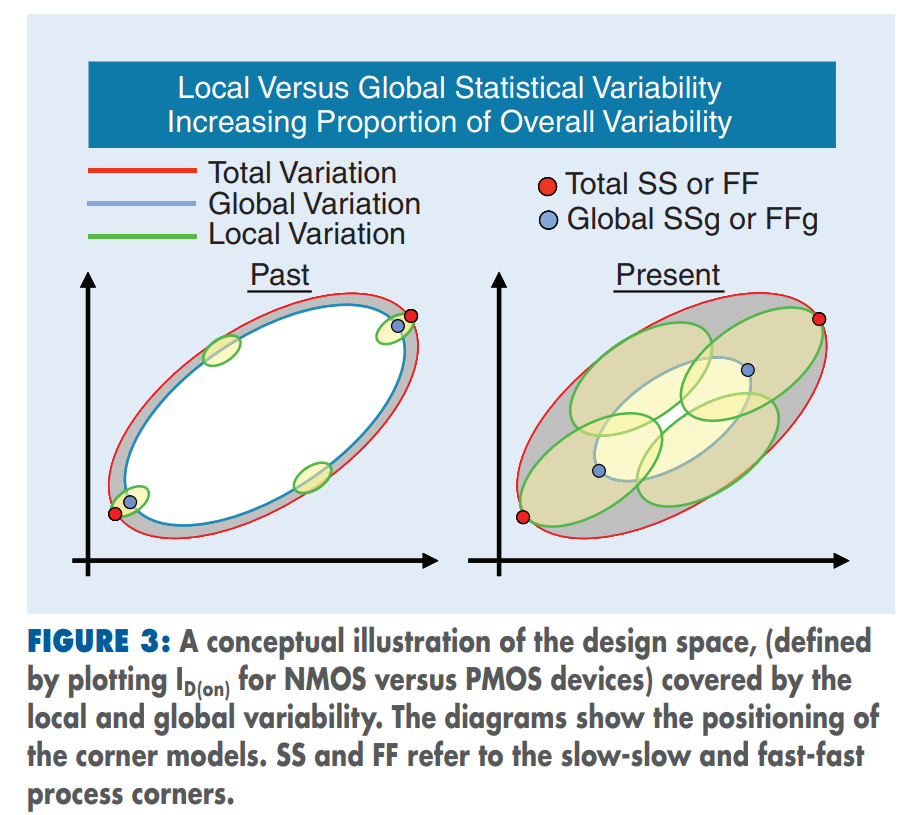
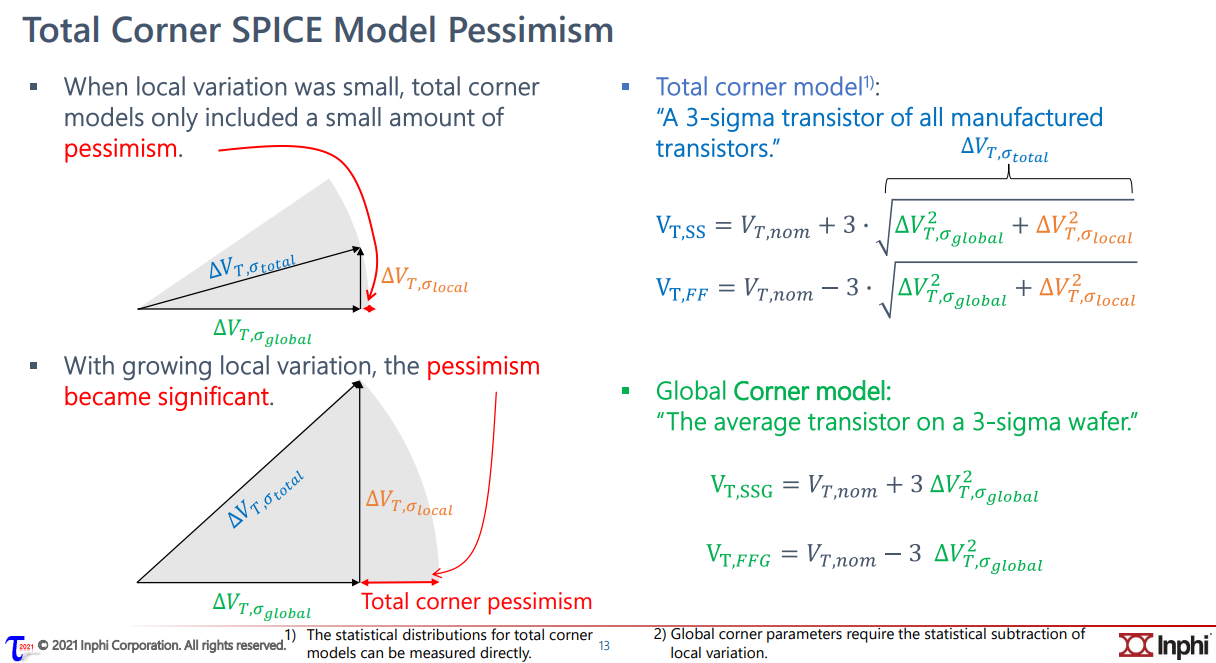
The "total corner" is representative of the maximum
device parameter variation including local device variation effects.
However, it is not a statistical corner.
The "global" corner is defined as the
"total" corner minus the impact of "local
variation"
Hence, if you were to examine simulation results for a parameter
using a "total" and "global" corner, you would find the range of
variation will be less with the "global" corner than with the "total"
corner.
The "global" corner is provided for use in statistical
simulations. Hence, when performing a Monte-Carlo simulation,
the "global" corner is selected - NOT the "total" corner.
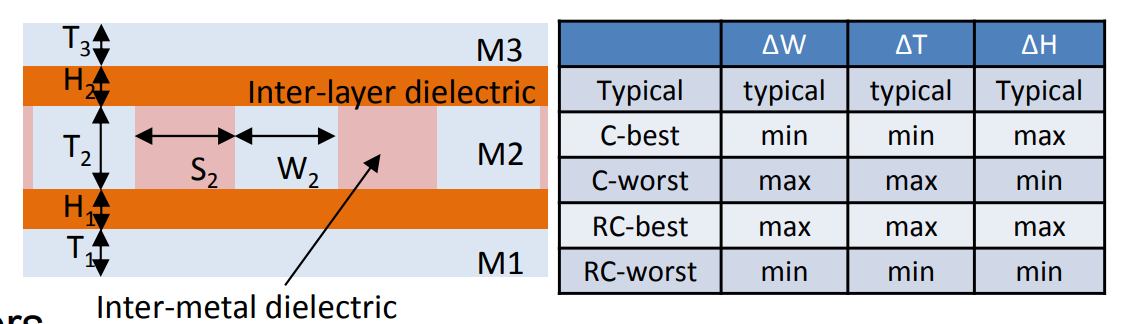
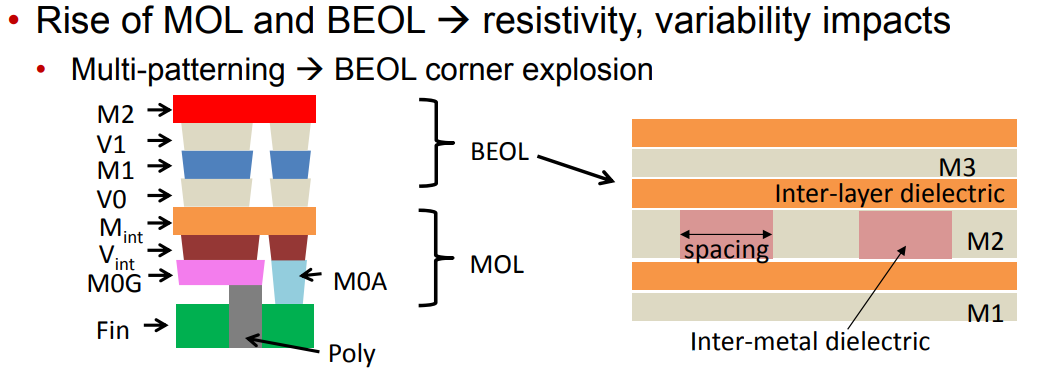
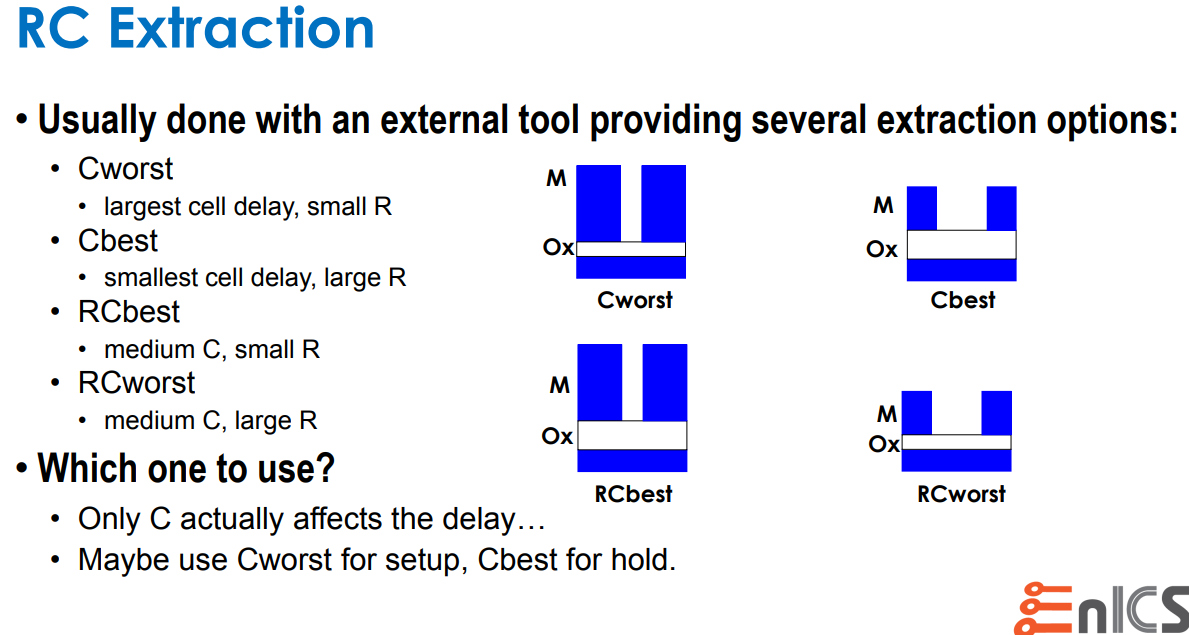
Metal width variation (\(\Delta
W\)), Metal thickness variation (\(\Delta T\)), IMD thickness variation (\(\Delta H\))
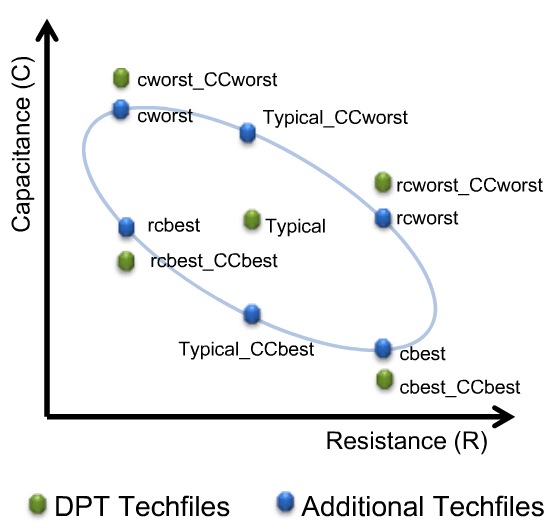
Capacitance Dominant: C-best, C-worst
Resistance Dominant: RC-best, RC-worst
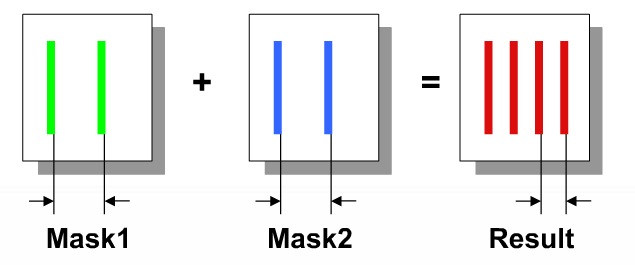
DPT effect
When using two masks per layer (Double Patterning Technology,
DPT) there is an issue of mask alignment where any
mis-alignment will cause layer spacing values to change, therefore
changing the parasitic coupling capacitance values.
Misalignment scale and direction are not deterministic facts:
coupling cap and total cap may be increased or decreased.
Five new corners are added in a DPT flow to account
for RC variations accurately:
sapced-dependent side-wall dielectric constant also affect coupling
cap
cworst_CCworst, cbest_CCbest, rcworst_CCworst, rcbest_CCbest and
typical
The others are for pre-color RC calculation purpose
_T stands for "Tighten DPT corner";
these are less pessimistic 1.5 sigma corners
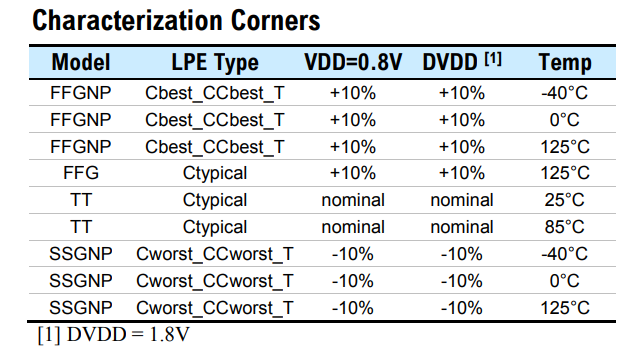
Below table is caputre of Aragio's TSMC16: LVDS datasheet
BEOL corner
Spacing variation is implicitly defined by \(\Delta W_m\).
We denote the conductor width and thickness of the layer m
by \(W_m\) and \(T_m\), respectively.
Similarly, we denote the thickness of the layer's interlayer
dielectric (i.e., the distance between layer m and layer m +1) by \(H_m\)
C-based means worst and best caps
RC-based means worst and best R in adjustment
with C (RC product)
Based on experience, it was found that C-based
extraction provides worst and best case over RC for internal
timing paths because Capacitance dominates short
wire.
However, for large design, inter-block timing paths were often worst
with RC worst parasitic since R dominates for
long wires.
signoff corners for setup &
hold
reference
Process Variation
Eric J.-W. Fang, T5: Fundamentals of Process Monitors for
Signoff-Oriented Circuit Design, 2022 IEEE International Solid-State
Circuits Conference
Alvin Loke, Device and Physical Design Considerations for Circuits in
FinFET Technology, ISSCC 2020 Short Course
Radojcic, Riko, Dan Perry and Mark Nakamoto. “Design for
manufacturability for fabless manufactuers.” IEEE Solid-State
Circuits Magazine 1 (2009): n. pag.
T. -B. Chan, S. Dobre and A. B. Kahng, "Improved signoff methodology
with tightened BEOL corners," 2014 IEEE 32nd International Conference on
Computer Design (ICCD), Seoul, Korea (South), 2014, pp. 311-316, doi:
10.1109/ICCD.2014.6974699.
Chan, T. (2014). Mitigation of Variability and Reliability Margins in
IC Implementation /. UC San Diego. ProQuest ID:
Chan_ucsd_0033D_14269. Merritt ID: ark:/20775/bb52916761. Retrieved from
https://escholarship.org/uc/item/35r1m001
primary
clock, generated clock and virtual clock in SDC
primary clocks
Primary clocks should be created at input ports and output pins of
black boxes.
Never create clocks on hierarchy pins. Creating clocks on hierarchy
will cause problems when reading SDF. The net timing arc becomes
segmented at the hierarchy and PrimeTime will be unable to annotate the
net successfully.
generated clocks
Generated clocks are generally created for waveform modifications of
a primary clock (not including simple inversions). PrimeTime does not
simulate a design and thus will not derive internally
generated clocks automatically - these clocks must be created by the
user and applied as a constraint.
PrimeTime caculate source latency for generated clocks if primary
clock is propagated, otherwise its source latency is
zero.
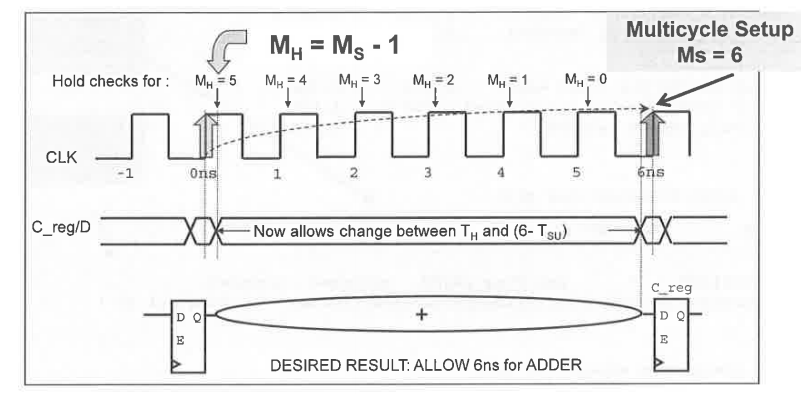
MH stands for Hold Multiplier, MS for Setup
Multiplier. The Setup multiplier counts up with increasing clock cycles,
the Hold Multiplier counts up with decreasing cycles. The origin (0) for
the Hold Multiplier is always at the Setup Multiplier - 1
position.
Reporting a
multicycle path with report_timing
1
report_timing -exceptions all -from *reg[26]/CP -to *reg/D
Timing Exceptions
If certain paths are not intended to operate
according to the default setup and hold behavior assumed by the
PrimeTime tool, you need to specify those paths as timing
exceptions. Otherwise, the tool might incorrectly report those paths as
having timing violations.
The PrimeTime tool lets you specify the following types of
exceptions:
False path – A path that is never sensitized due to the logic
configuration, expected data sequence, or operating mode.
Multicycle path – A path designed to take more than one clock cycle
from launch to capture.
Minimum or maximum delay path – A path that must meet a delay
constraint that you explicitly specify as a time value.
Error-[SV-LCM-PND] Package not defined ../sv/yapp_if.sv, 18 yapp_if, "yapp_pkg::" Package scope resolution failed. Token 'yapp_pkg' is not a package. Originating module 'yapp_if'. Move package definition before the use of the package.
place hw_top.svbefore or afteryapp_router.sv doesn't matter, the compiler (xrun, vcs)
can compile them successfully.
Conclusion
Always place package before DUT is preferred choice during
compiling.
Transaction Level Modeling
(TLM)
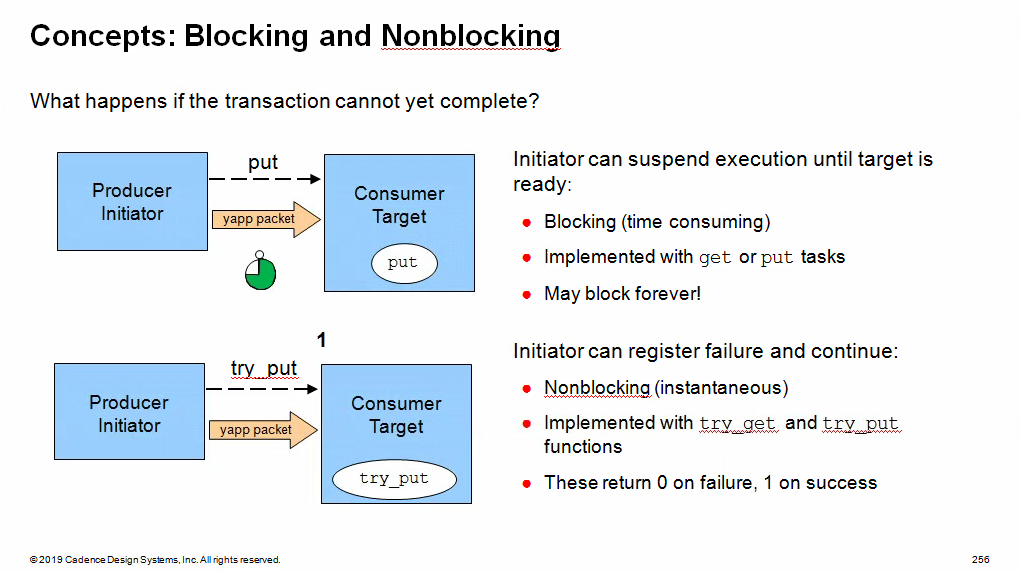
Blocking methods are defined with
get() or put()tasks to allow
them to consume time
Non-blocking methods are defined with
try_get() or try_put()functions as they execute in zero time
Uni-Directional TLM
Methods Reference
Method
Description
Syntax
put()
Blocking put
virtual task put(iput TR t);
try_put()
Nonblocking put -return 1 if successful -return 0 if
not
virtual function bit try_put(input TR t);
can_put()
Nonblocking test put -return 1 if put would be
successful -return 0 if not
virtual function bit can_put();
get()
Blocking get
virtual task get(output TR t);
try_get()
Nonblocking get -return 1 if successful -return 0 if
not
virtual function bit try_get(output TR t);
can_get()
Nonblocking test get -return 1 if get would be
successful -return 0 if not
virtual function bit can_get();
peek()
Blocking peek
virtual task peek(output TR t);
try_peek()
Nonblocking peek -return 1 if successful -return 0 if
not
virtual function bit try_peek(output TR t);
can_peek
Nonblocking test peek -return 1 if peek would be
successful -return 0 if not
virtual function bit can_peek();
The peek() methods are similarly to the
get() methods, but copy the transaction
instead of removing it. The transaction is not
consumed, and a subsequent get or peek
operation will return the same transaction
Selected Connector and
Method Options
put
try_put
can_put
get
try_get
can_get
peek
try_peed
can_peek
uvm_put_*
✓
✓
✓
uvm_blocking_put_*
✓
uvm_nonblocking_put_*
✓
✓
uvm_get_*
✓
✓
✓
uvm_blocking_get_*
✓
uvm_nonblocking_get_*
✓
✓
uvm_get_peek_*
✓
✓
✓
✓
✓
✓
uvm_blocking_get_peek_*
✓
✓
uvm_nonblocking_get_peek_*
✓
✓
✓
✓
in the connectors above, * can be replaced by
port, imp, or export
All the methods for a specific connector type MUST
be implemented. If you define an uvm_put connection between
two compoents, then the component with the uvm_put_imp
object must provide implementations of ALL three put
methods, put, try_put and
can_put, even if these methods are not explicitly
called
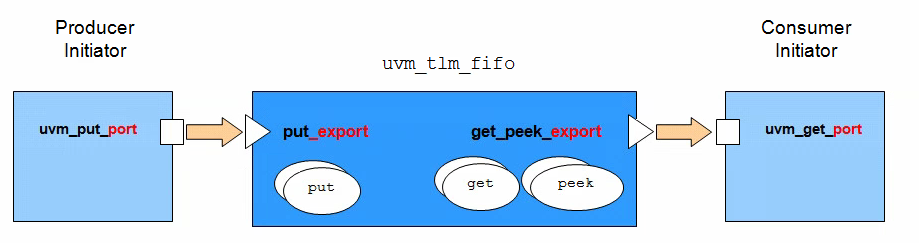
TLM FIFO
The TLM FIFO is a FIFO component wrapped in get and
putimp connectors. This has the benefit of
data storage as well as providing implementations of the communication
methods. Components connected to the TLM FIFO are in control of data
transfer and can simply defined port connectors to initiate read and
write operations on the FIFO
uvm_tlm_fifo
The TLM FIFO object is effectively a FIFO component instantiated
between and connected to two components. The FIFO contains
imp connectors for the standard TLM put and
get/peek interfaces, therefore the user does
not have to defineimp ports or communication methods and
the FIRO takes care of data storage
The advantages are:
The user does not need to define communication methods or
imp connectors
The FIFO provides data storage between the write
(put) and read
(get/peek) components
There are a number of built-in methods for checking FIFO status
The disadvantages are:
The user must now initiate both sides of the transfer (both
get/peek and put) to complete the
transaction
Two connections must be made (both sides of the FIFO) rather than
one
The put_export and get_peek_export
connection objects have alternatives which provide subsets of the full
connector. For example, blocking_put_export and
nonblocking_put_export can replace put_export.
blocking_get_export, nonblocking_get_export
and get_export (as well as others) can replace
get_peek_export.
built-in methods
Method
Description
Syntax
new
Standard component constructor with an additional third argument,
size, which sets the maximum FIFO size. Default size is 1.
A size of 0 is an unbounded FIFO
function new(string name, uvm_component parent=null, int size=1);
size
Return size of FIFO. 0 indicates unbounded
FIFO
virtual function int size()
used
Return number of entries written to the FIFO
virtual function int used();
is_empty
Return 1 if used() is 0, otherwise
0
virtual function bit is empty();
is_full
Return 1 if used() is equal to size,
otherwise 0
virtual function bit is_full()
flush
Delete all entries from the FIFO, upon which used() is
0 and is_empty() is
1
virtual funciton void flush();
1 2 3
class uvm_tlm_fifo #(type T=int) extends uvm_tlm_fifo_base #(T); ... endclass
virtualclass uvm_tlm_fifo_base #(type T=int)extends uvm_component; uvm_put_imp #(T, this_type) put_export; uvm_get_peek_imp #(T, this_type) get_peek_export; uvm_analysis_port #(T) put_ap; uvm_analysis_port #(T) get_ap; // The following are aliases to the above put_export uvm_put_imp #(T, this_type) blocking_put_export; uvm_put_imp #(T, this_type) nonblocking_put_export; // The following are all aliased to the above get_peek_export, which provides // the superset of these interfaces. uvm_get_peek_imp #(T, this_type) blocking_get_export; uvm_get_peek_imp #(T, this_type) nonblocking_get_export; uvm_get_peek_imp #(T, this_type) get_export; uvm_get_peek_imp #(T, this_type) blocking_peek_export; uvm_get_peek_imp #(T, this_type) nonblocking_peek_export; uvm_get_peek_imp #(T, this_type) peek_export; uvm_get_peek_imp #(T, this_type) blocking_get_peek_export; uvm_get_peek_imp #(T, this_type) nonblocking_get_peek_export; functionnew(string name, uvm_component parent = null); super.new(name, parent); put_export = new("put_export", this); blocking_put_export = put_export; nonblocking_put_export = put_export; get_peek_export = new("get_peek_export", this); blocking_get_peek_export = get_peek_export; nonblocking_get_peek_export = get_peek_export; blocking_get_export = get_peek_export; nonblocking_get_export = get_peek_export; get_export = get_peek_export; blocking_peek_export = get_peek_export; nonblocking_peek_export = get_peek_export; peek_export = get_peek_export; put_ap = new("put_ap", this); get_ap = new("get_ap", this); endfunction
Analysis FIFO
uvm_tlm_analysis_fifo
uvm_tlm_analysis_fifo is a specialization of
uvm_tlm_fifo
Intended to buffer write transactions between the UVC monitor
analysis port and scoreboard
It has the following characteristics:
Unbounded (size=0)
analysis_export connector replaces
put_export
Support the analysis write method
By declaring the FIFO in the scoreboard, we can get
directly from the FIFO output.
However the write side connection of the FIFO to the interface UVC
monitor analysis port must be made (usually) in the testbench which has
visibility of both UVC and scoreboard components. The connection is made
using a connect method call inside the connect phase method
class uvm_tlm_analysis_fifo #(type T = int) extends uvm_tlm_fifo #(T);
// Port: analysis_export #(T) // // The analysis_export provides the write method to all connected analysis // ports and parent exports: // //| function void write (T t) // // Access via ports bound to this export is the normal mechanism for writing // to an analysis FIFO. // See write method of <uvm_tlm_if_base #(T1,T2)> for more information.
// Function: new // // This is the standard uvm_component constructor. ~name~ is the local name // of this component. The ~parent~ should be left unspecified when this // component is instantiated in statically elaborated constructs and must be // specified when this component is a child of another UVM component.
functionnew(string name , uvm_component parent = null); super.new(name, parent, 0); // analysis fifo must be unbounded analysis_export = new("analysis_export", this); endfunction
functionvoid write(input T t); void'(this.try_put(t)); // unbounded => must succeed endfunction
endclass
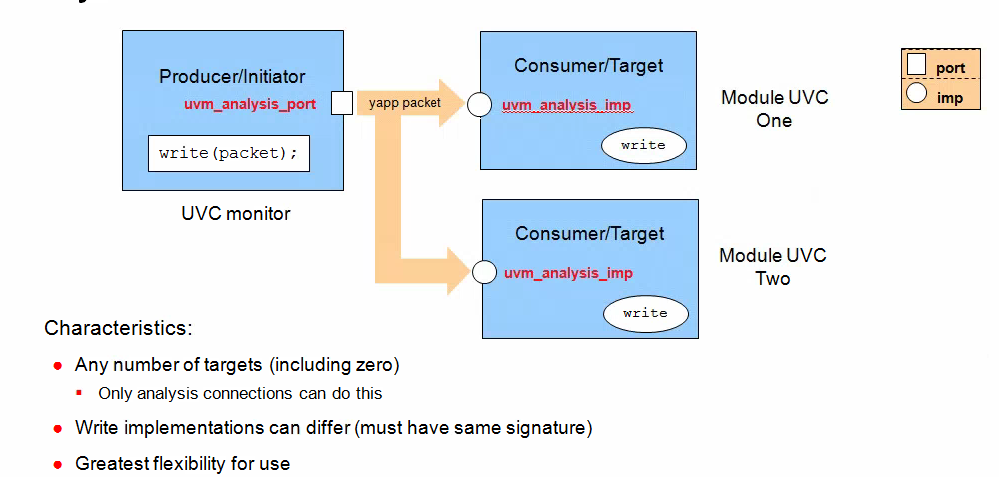
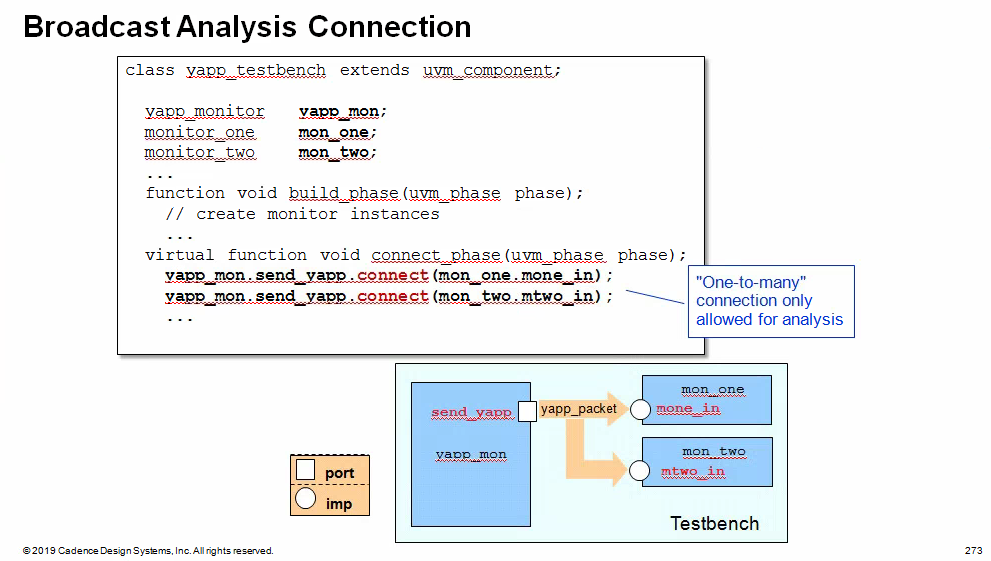
Analysis Port Broadcast
Analysis ports can (uniquely) be connected to any number of
imp connectors, including zero
The analysis port in component yapp_monitor will be
connected to both monitor_one and monitor_two
components. Each of the receiving components has an analysis imp
object and a write communication method declared. The write method
must have the same signature - i.e., they must be void functions called
write with a single input argument of type yapp_packet, but
their implementations can be completely different.
When the send_yapp port is connected to both
mone_in and mtwo_in imps, then a single write call
from yapp_monitor executes both write implementations in
monitor_one and monitor_two
For non-analysis connections
the TLM object must be connected to a single destination only, i.e.,
each non-analysis object has exactly one connect call.
An object may be used multiple times as the argument to a
connect, but exactly once as the caller. This is called
many-to-one connection. For example, many ports can be
connected to a one imp connector
For analysis connections
a TLM object can be connected to any number of destinations i.e.,
one analysis object can call connect many times. This is called
one-to-many connection. For example, one port can be
connected to many imp connectors. one-to-many is only
allowed for analysis connections. An analysis connection can also
NOT call connect. An unconnected TLM object is also only
allowed for analysis connections
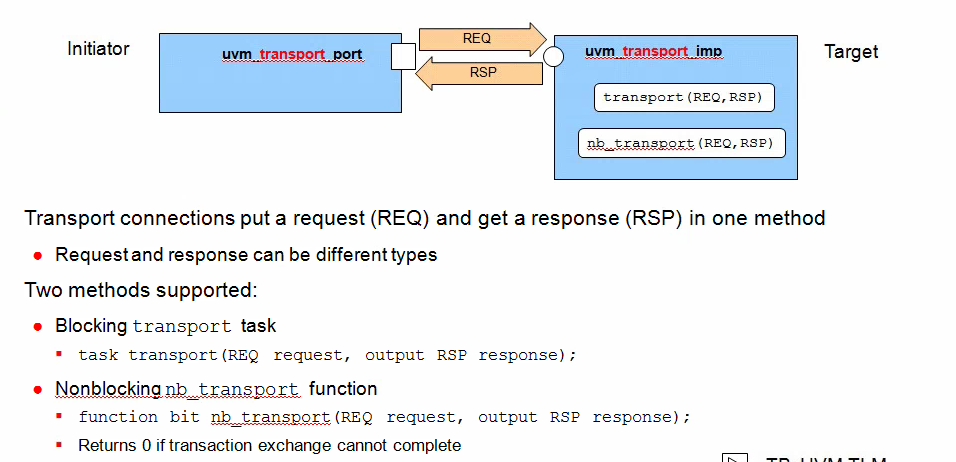
Bi-Directional TLM
Transport Connection
Connector syntax
1 2 3
uvm_blocking_transport_XXX #(type REA, type RSP) uvm_nonblocking_transport_XXX #(type REQ, type RSP) uvm_transport_XXX #(type REQ, type RSP)
FIFO/analysis FIFOs do not perform any cloning on input transactions.
Therefore, you will need to check that the UVC monitors collect every
transaction into a different instance to avoid overwriting data in the
FIFOs
class uvm_reg_map extends uvm_object; // Function: add_submap // // Add an address map // // Add the specified address map instance to this address map. // The address map is located at the specified base address. // The number of consecutive physical addresses occupied by the submap // depends on the number of bytes in the physical interface // that corresponds to the submap, // the number of addresses used in the submap and // the number of bytes in the // physical interface corresponding to this address map. // // An address map may be added to multiple address maps // if it is accessible from multiple physical interfaces. // An address map may only be added to an address map // in the grand-parent block of the address submap. // externvirtualfunctionvoid add_submap (uvm_reg_map child_map, uvm_reg_addr_t offset);
// Function: add_mem // // Add a memory // // Add the specified memory instance to this address map. // The memory is located at the specified base address and has the // specified access rights ("RW", "RO" or "WO"). // The number of consecutive physical addresses occupied by the memory // depends on the width and size of the memory and the number of bytes in the // physical interface corresponding to this address map. // // If ~unmapped~ is TRUE, the memory does not occupy any // physical addresses and the base address is ignored. // Unmapped memories require a user-defined ~frontdoor~ to be specified. // // A memory may be added to multiple address maps // if it is accessible from multiple physical interfaces. // A memory may only be added to an address map whose parent block // is the same as the memory's parent block. // externvirtualfunctionvoid add_mem (uvm_mem mem, uvm_reg_addr_t offset, string rights = "RW", bit unmapped=0, uvm_reg_frontdoor frontdoor=null);
The generic register item is implemented as a struct in order to
minimise the amount of memory resource it uses. The struct is defined as
type uvm_reg_bus_op and this contains 6 fields:
Property
Type
Comment/Description
addr
uvm_reg_addr_t
Address field, defaults to 64 bits
data
uvm_reg_data_t
Read or write data, defaults to 64 bits
kind
uvm_access_e
UVM_READ or UVM_WRITE
n_bits
unsigned int
Number of bits being transferred
byte_en
uvm_reg_byte_en_t
Byte enable
status
uvm_status_e
UVM_IS_OK, UVM_IS_X, UVM_NOT_OK
1 2 3 4 5 6 7 8 9
typedefstruct { uvm_access_e kind; // Kind of access: READ or WRITE. uvm_reg_addr_t addr; // The bus address. uvm_reg_data_t data; // The data to write. // The number of bits of <uvm_reg_item::value> being transferred by this transaction. int n_bits; uvm_reg_byte_en_t byte_en; // Enables for the byte lanes on the bus. uvm_status_e status; // The result of the transaction: UVM_IS_OK, UVM_HAS_X, UVM_NOT_OK. } uvm_reg_bus_op;
The register class contains a build method which is used
to create and configure the
fields.
this build method is not called by the UVM
build_phase, since the register is an
uvm_object rather than an uvm_component
1 2 3 4 5 6
// // uvm_reg constructor prototype: // functionnew (string name="", // Register name intunsigned n_bits, // Register width in bits int has_coverage); // Coverage model supported by the register
As shown above, Register width is 32 same with the
bus width, lower 14 bit is configured.
RTL
1 2
`define SPI_CTRL_BIT_NB 14 reg [`SPI_CTRL_BIT_NB-1:0] ctrl; // Control and status register
Register Maps
Two purpose of the register map
provide information on the offset of the registers, memories and/or
register blocks
identify bus agent based sequences to be executed ???
There can be several register maps within a block, each one can
specify a different address map and a different
target bus agent
register map has to be created which the register
block using the create_map method
1 2 3 4 5 6 7 8 9 10 11 12 13
// // Prototype for the create_map method // function uvm_reg_map create_map(string name, // Name of the map handle uvm_reg_addr_t base_addr, // The maps base address intunsigned n_bytes, // Map access width in bytes uvm_endianness_e endian, // The endianess of the map bit byte_addressing=1); // Whether byte_addressing is supported // // Example: // AHB_map = create_map("AHB_map", 'h0, 4, UVM_LITTLE_ENDIAN);
The n_bytes parameter is the word size (bus
width) of the bus to which the map is associated. If a register's width
exceeds the bus width, more than one bus access is needed to read and
write that register over that bus.
he byte_addressing argument affects how the address is
incremented in these consecutive accesses. For example, if
n_bytes=4 and byte_addressing=0, then an access to a
register that is 64-bits wide and at offset 0 will result in two bus
accesses at addresses 0 and 1. With byte_addressing=1, that
same access will result in two bus accesses at addresses 0 and 4.
The default for byte_addressing is
1
The first map to be created within a register
block is assigned to the default_map member of the
register block
Register Adapter
uvm_reg_adapter
Methods
Description
reg2bus
Overload to convert generic register access items to target bus
agent sequence items
bus2reg
Overload to convert target bus sequence items to register model
items
Properties (Of type bit)
Description
supports_byte_enable
Set to 1 if the target bus and the target bus agent supports byte
enables, else set to 0
provides_responses
Set to 1 if the target agent driver sends separate response
sequence_items that require response handling
The provides_responses bit should be set if the
agent driver returns a separate response item (i.e.
put(response), or item_done(response)) from
its request item
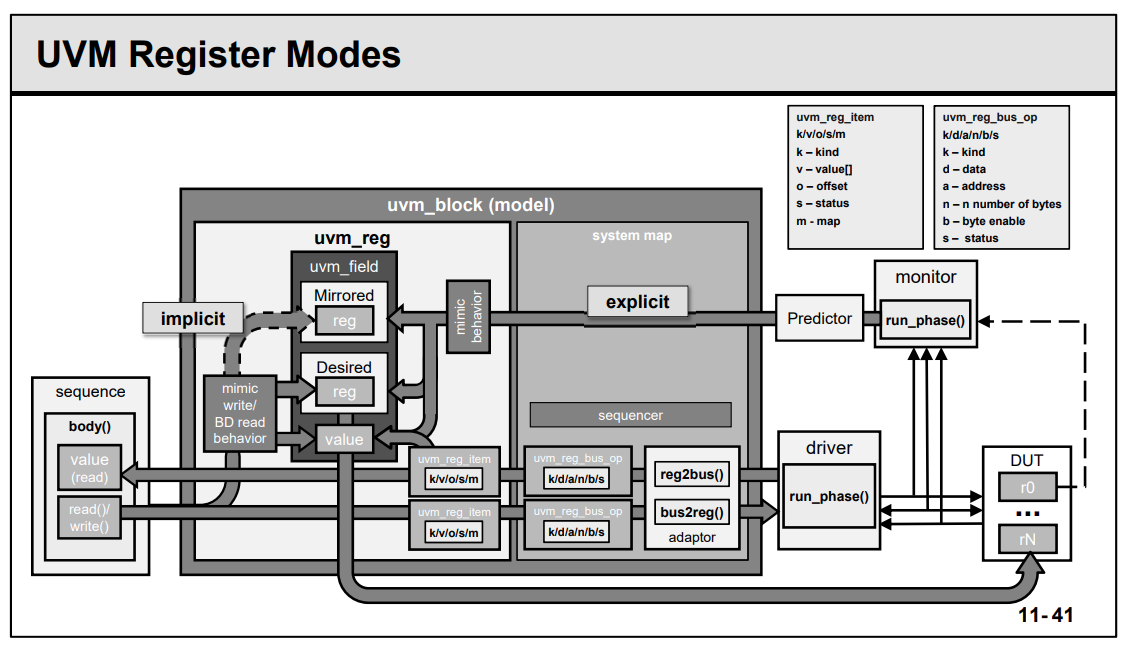
Prediction
the update, or prediction, of the register model content can occur
using one of three models
Auto Prediction
This mode of operation is the simplest to implement, but suffers from
the drawback that it can only keep the register model up to date with
the transfers that it initiates. If any other sequences
directly access the target sequencer to update register content, or if
there are register accesses from other DUT interfaces, then the register
model will not be updated.
// Gets the auto-predict mode setting for this map. functionbit uvm_reg_map::get_auto_predict(); return m_auto_predict; endfunction
// Function: set_auto_predict
//
// Sets the auto-predict mode for his map.
//
// When on is TRUE,
// the register model will automatically update its
mirror (what it thinks should be in the DUT)
immediately after any bus read or write operation via this map.
Before a uvm_reg::write
// or uvm_reg::read operation returns, the register's
uvm_reg::predict method is called to update
the mirrored value in the register.
//
// When on is FALSE, bus reads and writes via
this map do not
// automatically update the mirror. For real-time updates to the
mirror
// in this mode, you connect a uvm_reg_predictor
instance to the bus
// monitor. The predictor takes observed bus transactions from
the
// bus monitor, looks up the associated uvm_reg register
given
// the address, then calls that register's
uvm_reg::predict method.
// While more complex, this mode will capture all register
read/write
// activity, including that not directly descendant from calls to
// uvm_reg::write and uvm_reg::read.
//
// By default, auto-prediction is turned off.
//
The register model content is updated based on the register accesses
it initiates
Explicit Prediction
(Recommended Approach)
Explicit prediction is the default mode of
prediction
The register model content is updated via the predictor
component based on all observed bus transactions, ensuring that
register accesses made without the register model are mirrored
correctly. The predictor looks up the accessed register by address then
calls its predict() method
if (m_is_busy && kind == UVM_PREDICT_DIRECT) begin `uvm_warning("RegModel", {"Trying to predict value of register '", get_full_name(),"' while it is being accessed"}) rw.status = UVM_NOT_OK; return; end foreach (m_fields[i]) begin rw.value[0] = (reg_value >> m_fields[i].get_lsb_pos()) & ((1 << m_fields[i].get_n_bits())-1); m_fields[i].do_predict(rw, kind, be>>(m_fields[i].get_lsb_pos()/8)); end
UVM_PREDICT_DIRECT: begin if (m_parent.is_busy()) begin `uvm_warning("RegModel", {"Trying to predict value of field '", get_name(),"' while register '",m_parent.get_full_name(), "' is being accessed"}) rw.status = UVM_NOT_OK; end end endcase
// update the mirror with predicted value m_mirrored = field_val; m_desired = field_val; this.value = field_val;
endfunction: do_predict
uvm_access_e
1 2 3 4 5 6 7 8 9 10 11 12 13
// Enum: uvm_access_e // // Type of operation begin performed // // UVM_READ - Read operation // UVM_WRITE - Write operation // typedefenum { UVM_READ, UVM_WRITE, UVM_BURST_READ, UVM_BURST_WRITE } uvm_access_e;
uvm_predict_e
1 2 3 4 5 6 7 8 9 10 11 12 13
// Enum: uvm_predict_e // // How the mirror is to be updated // // UVM_PREDICT_DIRECT - Predicted value is as-is // UVM_PREDICT_READ - Predict based on the specified value having been read // UVM_PREDICT_WRITE - Predict based on the specified value having been written // typedefenum { UVM_PREDICT_DIRECT, UVM_PREDICT_READ, UVM_PREDICT_WRITE } uvm_predict_e;
uvm_path_e
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
// Enum: uvm_path_e // // Path used for register operation // // UVM_FRONTDOOR - Use the front door // UVM_BACKDOOR - Use the back door // UVM_PREDICT - Operation derived from observations by a bus monitor via // the <uvm_reg_predictor> class. // UVM_DEFAULT_PATH - Operation specified by the context // typedefenum { UVM_FRONTDOOR, UVM_BACKDOOR, UVM_PREDICT, UVM_DEFAULT_PATH } uvm_path_e;
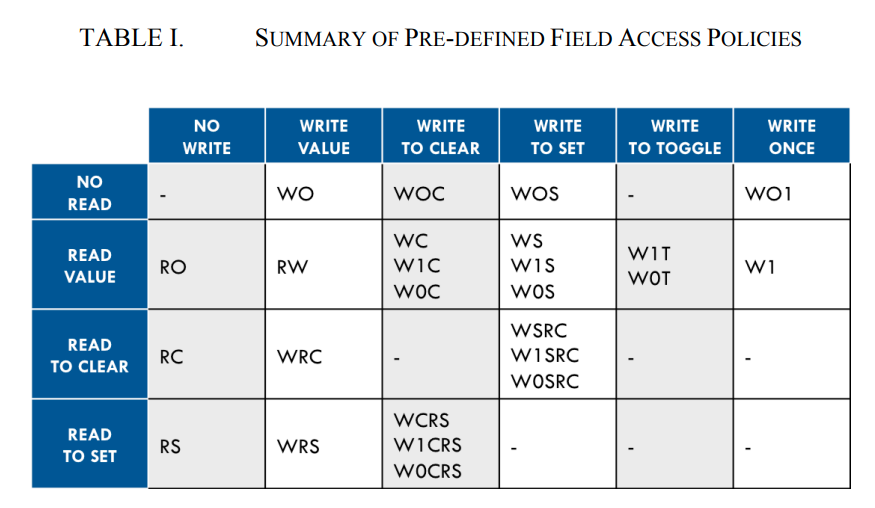
whether a register field can be read or written depends on both the
field's configured access policy and the register's rights in the map
being used to access the field
If a back-door access path is used, the effect of writing the
register through a physical access is mimicked. For example,
read-only bits in the registers will
not be written.
The mirrored value will be updated using the
uvm_reg::predict() method.
If a back-door access path is used, the effect of reading the
register through a physical access is mimicked. For example,
clear-on-read bits in the registers will be set to
zero.
The mirrored value will be updated using the
uvm_reg::predict() method.
Sample the value in the DUT register corresponding to this
abstraction class instance using a back-door access.
The register value is sampled, not modified.
Uses the HDL path for the design abstraction specified by
kind.
The mirrored value will be updated using the
uvm_reg::predict() method.
Read the register and optionally compared the readback
value with the current mirrored value if
check is UVM_CHECK.
The mirrored value will be updated using the
uvm_reg::predict() method based on the readback
value.
The mirroring can be performed using the physical interfaces
(frontdoor) or uvm_reg::peek() (backdoor).
If the register contains write-only fields,
their content is mirrored and optionally checked only if a
UVM_BACKDOOR access path is used to read the
register.
Write this register if the DUT register is out-of-date with the
desired/mirrored value in the abstraction class, as determined by the
uvm_reg::needs_update() method.
The update can be performed using the using the physical interfaces
(frontdoor) or uvm_reg::poke() (backdoor) access.
functionbit uvm_reg::needs_update(); needs_update = 0; foreach (m_fields[i]) begin if (m_fields[i].needs_update()) begin return1; end end endfunction: needs_update
// Concatenate the write-to-update values from each field // Fields are stored in LSB or MSB order upd = 0; foreach (m_fields[i]) upd |= m_fields[i].XupdateX() << m_fields[i].get_lsb_pos();
Update the mirrored and desired value for this
register.
Predict the mirror (and desired) value of the fields in the register
based on the specified observed value on a specified
address map, or based on a calculated value.
if (rw.status ==UVM_IS_OK ) rw.status = UVM_IS_OK;
if (m_is_busy && kind == UVM_PREDICT_DIRECT) begin `uvm_warning("RegModel", {"Trying to predict value of register '", get_full_name(),"' while it is being accessed"}) rw.status = UVM_NOT_OK; return; end
foreach (m_fields[i]) begin rw.value[0] = (reg_value >> m_fields[i].get_lsb_pos()) & ((1 << m_fields[i].get_n_bits())-1); m_fields[i].do_predict(rw, kind, be>>(m_fields[i].get_lsb_pos()/8)); end
UVM_PREDICT_DIRECT: begin if (m_parent.is_busy()) begin `uvm_warning("RegModel", {"Trying to predict value of field '", get_name(),"' while register '",m_parent.get_full_name(), "' is being accessed"}) rw.status = UVM_NOT_OK; end end endcase
// update the mirror with predicted value m_mirrored = field_val; m_desired = field_val; this.value = field_val;
Resetting a register model sets the mirror to the reset value
specified in the model
uvm_reg::reset
1 2 3 4 5 6 7 8 9 10
functionvoid uvm_reg::reset(string kind = "HARD"); foreach (m_fields[i]) m_fields[i].reset(kind); // Put back a key in the semaphore if it is checked out // in case a thread was killed during an operation void'(m_atomic.try_get(1)); m_atomic.put(1); m_process = null; Xset_busyX(0); endfunction: reset
m_mirrored = m_reset[kind]; m_desired = m_mirrored; value = m_mirrored;
if (kind == "HARD") m_written = 0;
endfunction: reset
uvm_reg_field::randomize
uvm_reg_field::pre_randomize()
Update the only publicly known property value with the
current desired value so it can be used as a state
variable should the rand_mode of the field be turned
off.
value is m_desired if
rand_mode is off.
1 2 3
functionvoid uvm_reg_field::pre_randomize(); value = m_desired; endfunction: pre_randomize
// Enum: uvm_predict_e // // How the mirror is to be updated // // UVM_PREDICT_DIRECT - Predicted value is as-is // UVM_PREDICT_READ - Predict based on the specified value having been read // UVM_PREDICT_WRITE - Predict based on the specified value having been written // typedefenum { UVM_PREDICT_DIRECT, UVM_PREDICT_READ, UVM_PREDICT_WRITE } uvm_predict_e;
UVM REG RALF & IP-XACT
UVM Register Abstraction Layer Generator User Guide, S-2021.09-SP1,
December 2021
class ral_reg_CTRL extends uvm_reg; class ral_reg_STAT extends uvm_reg; class ral_reg_HTIM extends uvm_reg; class ral_reg_VTIM extends uvm_reg; class ral_reg_C1CR extends uvm_reg; class ral_mem_CLUT1 extends uvm_mem; class ral_block_vga_lcd extends uvm_reg_block;
ralgen command
1
ralgen -uvm -t dut_regmodel0 vga_lcd_env.ralf
BYTE or HALFWORD access
User is verifying 32 bit registers and the design also allows the
BYTE (8 bits) and HALFWORD (16 bits) accesses.
this is achieved by setting the bit_addressing=0
field in the uvm_reg_block::create_map function.
Using create_map in uvm_reg_block, you can
change the type of addressing scheme you want to use; namely BYTE or
HALFWORD.
this.maps[map] = 1; if (maps.num() == 1) default_map = map;
return map; endfunction
uvm_reg_map::add_reg
The register is located at the specified address offset from
this maps configured base address.
The number of consecutive physical addresses occupied by the register
depends on the width of the register and the number of bytes in the
physical interface corresponding to this address map.
If unmapped is TRUE, the register does not occupy any
physical addresses and the base address is ignored. Unmapped registers
require a user-defined frontdoor to be specified.
functionvoid uvm_reg_map::add_reg(uvm_reg rg, uvm_reg_addr_t offset, string rights = "RW", bit unmapped=0, uvm_reg_frontdoor frontdoor=null);
if (m_regs_info.exists(rg)) begin `uvm_error("RegModel", {"Register '",rg.get_name(), "' has already been added to map '",get_name(),"'"}) return; end
if (rg.get_parent() != get_parent()) begin `uvm_error("RegModel", {"Register '",rg.get_full_name(),"' may not be added to address map '", get_full_name(),"' : they are not in the same block"}) return; end rg.add_map(this);
begin uvm_reg_map_info info = new; info.offset = offset; info.rights = rights; info.unmapped = unmapped; info.frontdoor = frontdoor; m_regs_info[rg] = info; end endfunction
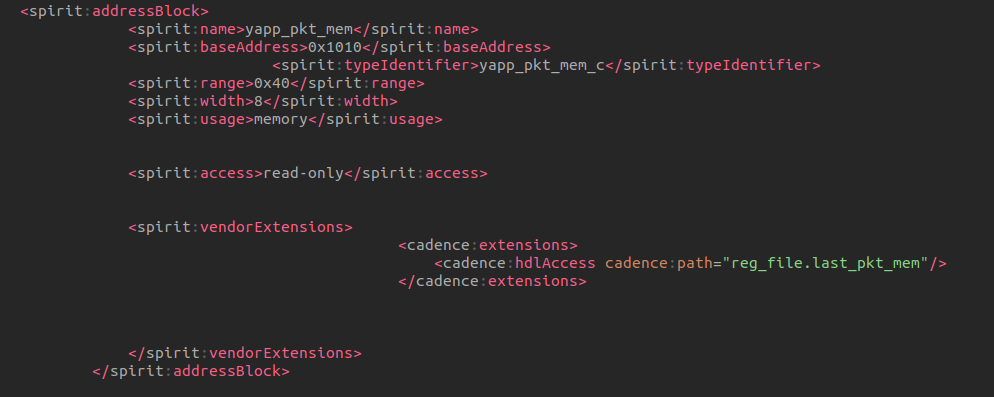
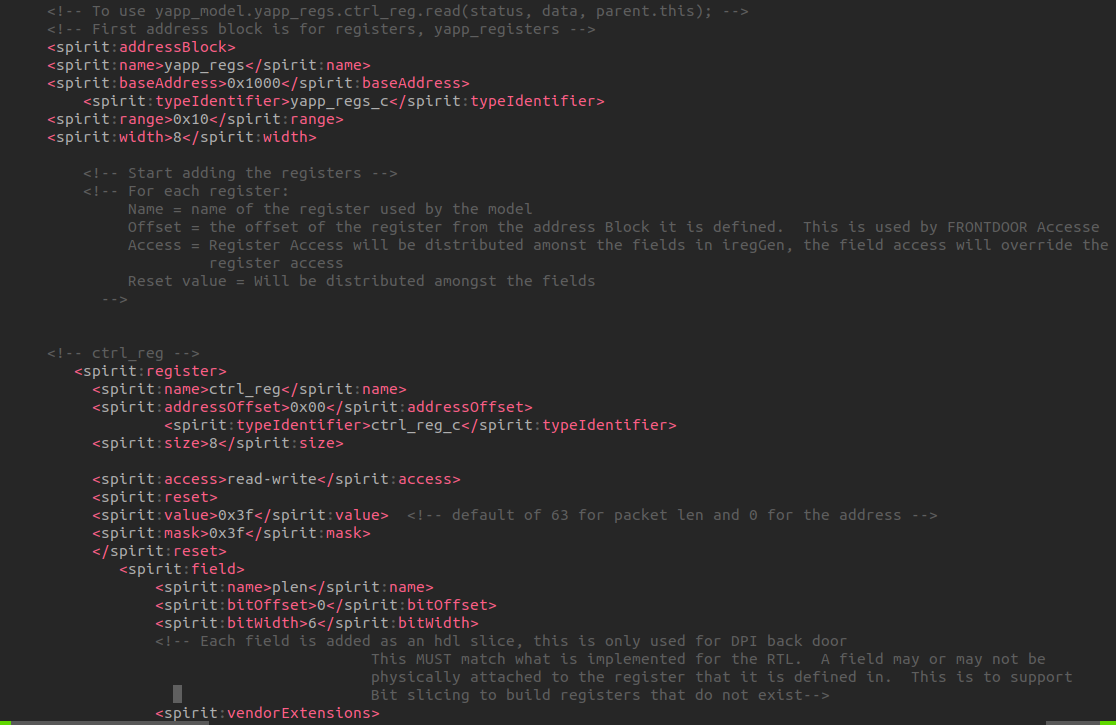
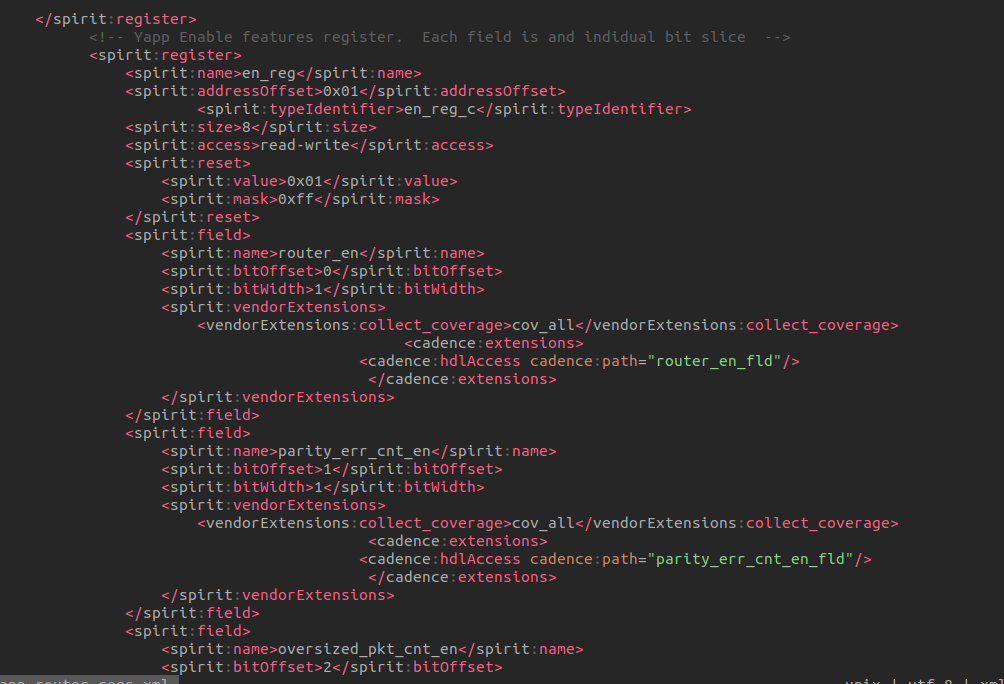
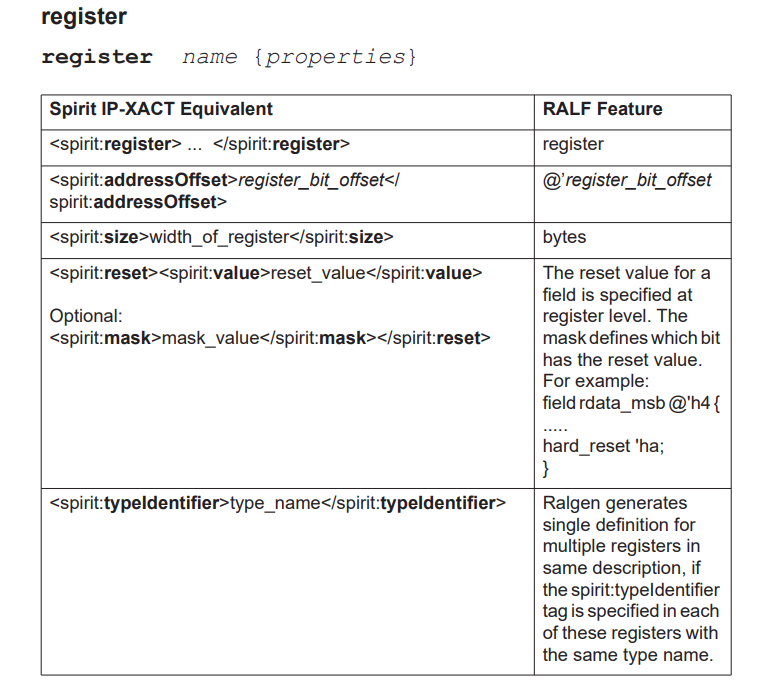
a register has an addressOffset that describes the
location of the register expressed in addressUnitBits as
offset to the starting address of the containing
addressBlock or the containing
registerFile
addressUnitBits
The addressUnitBits element describes the number of bits
of an address increment between two consecutive addressable
units in the addressSpace. If
addressUnitBits is not described, then its value
defaults to 8, indicating a
byte-addressableaddressSpace
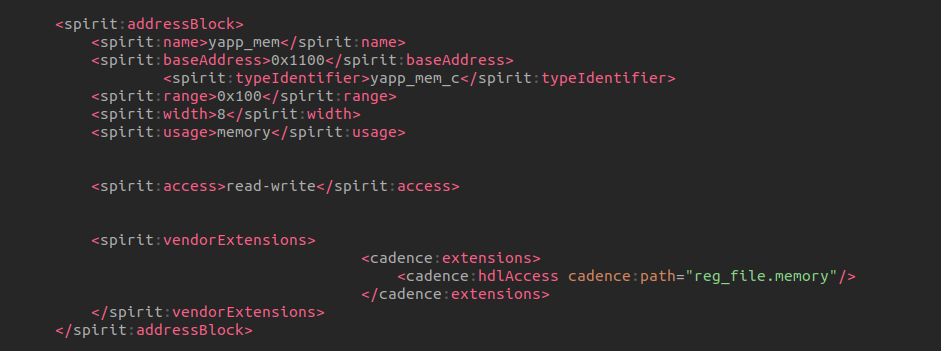
block
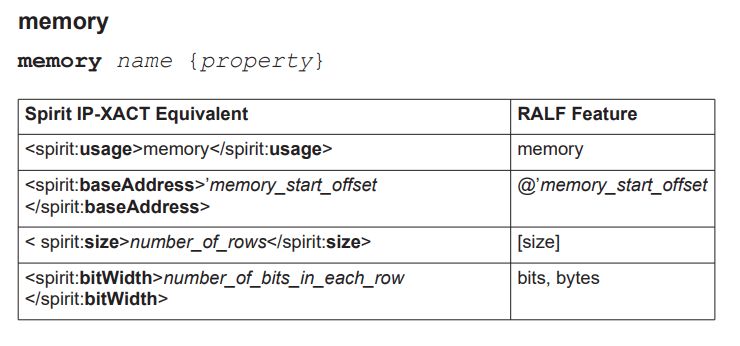
memory
Global Handles in UVM
Mechanism in UVM-1.1
1 2 3 4 5
functionvoid test_base::start_of_simulation_phase(uvm_phase phase); super.start_of_simulation_phase(phase); uvm_top.print_topology(); // Will not compile in UVM-1.2 factory.print(); // Will not compile in UVM-1.2 endfunction
Global handles uvm_top and factory in uvm_pkg have been removed in
UVM-1.2 and later
Mechanism in UVM-1.1 and
UVM-1.2
Call the get() method of the class to retrieve the
singleton handle.
1 2 3 4 5
functionvoid test_base::start_of_simulation_phase(uvm_phase phase); super.start_of_simulation_phase(phase); uvm_root::get().print_topology(); // Works in UVM-1.1 & UVM-1.2 uvm_factory::get().print(); // Works in UVM-1.1 & UVM-1.2 endfunction
uvm_coreservice_t is the uvm-1.2 mechanism for
accessing all the central UVM services such as
uvm_root,uvm_factory,
uvm_report_server, etc.
1 2 3 4 5 6 7
// Using the uvm_coreservice_t: uvm_coreservice_t cs; uvm_factory f; uvm_root top; cs = uvm_coreservice_t::get(); f = cs.get_factory(); top = cs.get_root();
As you can see , the uvm_config_db::set is after the
factory type_id::create, but receive_value
is still 100, I believe that build_phase
of upper hierarchy finish first before create lower components.
But the recommendation in literature and many web is place
uvm_config_db::set before create
// YAPP Interface to the DUT yapp_if in0(clock, reset); // reset will now be generated by the Clock and Reset UVC // input: clock; output: reset, run_clock, clock_period clock_and_reset_if clk_rst_if(.clock(clock), .reset(reset), .run_clock(run_clock), .clock_period(clock_period)); hbus_if hif(.clock(clock), .reset(reset));
imp and port connectors are sufficient for
modeling most connections, but there is third connector,
export, which is used exclusively in hierarchical
connections.
Normally hierarchical routing is not required. A port on
an UVC monitor can be connected directly to an imp in a
scoreboard by specifying full hierarchical pathname (e.g.,
env.agent.monitor.analysis_port). The structure of an UVC is fixed and
so the user knows to look in the monitor component for the analysis
ports.
However the internal hierarchy of a module UVC is more arbitrary, and
it may be convenient to route all the module UVC connectors to the top
level to allow use without knowledge of the internal structure.
On the initiator side
ports are routed up the hierarchy via other port instances
On the target side
only the component which defines the communication method is allowed
to have an imp instance. So we need a third object to route
connections up the target side hierarchy - export
The hierarchical route must be connected at each level in the
direction of control flow:
1
initiator.connect(target)
Connection rules are as follows:
port initiators can be connected to port,
export or imp targets
export initiators can be connected to
export or imp targets
imp cannot be connection initiator. imp is
target only and is always the last connection object on a route
uvm_analysis_port
1 2 3
class uvm_analysis_port # ( type T = int ) extends uvm_port_base # (uvm_tlm_if_base #(T,T))
uvm_analysis_port
1 2 3
class uvm_analysis_port # ( type T = int ) extends uvm_port_base # (uvm_tlm_if_base #(T,T))
uvm_analysis_imp
1 2 3 4
class uvm_analysis_imp #( type T = int, type IMP = int ) extends uvm_port_base #(uvm_tlm_if_base #(T,T))
QA
What are the three distinct functions of a scoreboard?
Reference model, expected data storage and comparison
To how many consumer components can an analysis port be
connected?
Any number, including zero
What are the names of the two declarations made available by the
following macro:
1
`uvm_analysis_imp_decl(_possible)
Subclass uvm_analysis_imp_possible
Method write_possible
Why should a scoreboard clone the data received by a
write method?
The write method only sends a reference, therefore if
the sending component uses the same reference for every data item,
overwriting of data in the storage function of the scoreboard is
possible without cloning.
Debug topology and
Check config usage in UVM
Topology of the test
1 2 3
functionvoid test_base::start_of_simulation_phase(uvm_phase phase); uvm_root::get().print_topology(); // defaults to table printer endfunction
The default printer policy is
uvm_default_table_printer
There are three default printer policies that the uvm_pkg
provides:
Check all configuration settings in a components configuration table
to determine if the setting has been used, overridden or not used. When
recurse is 1 (default), configuration for this and all child
components are recursively checked. This function is automatically
called in the check phase, but can be manually called at any time.
To get all configuration information prior to the run phase, do
something like this in your top object:
Control-oriented coverage uses SystemVerilog Assertion (SVA) syntax
and the cover directive. It is used to cover sequences of signal values
over time. Assertions cannot be declared or "covered" in a class
declaration, so their use in an UVM verification environment is
restricted to interface only
Covergroup for
data-oriented coverage
CAN be declared as a class member and created in class
constructor
Data-oriented coverage uses the covergroup construct.
Covergroups can be declared and created in classes, therefore they are
essential for explicit coverage in a UVM verification environment.
Interface Monitor Coverage
covergroup new constructor is called
directly off the declaration of the covergroup, it does
not have a separate instance name
1
collected_pkts_cq = new();
The covergroup instance must be created in the class
constructor, not a UVM build_phase or other phase
method
Routing - packets flow from input ports to all legal outputs
latency - all packets received within speicied delay
The module UVC monitor receives data from the interface monitors via
analysis ports, so the implementation of the analysis write function is
a convenient place to put coverage code
run_test search testcase in
UVM
It depends on the simulator:
QuestaSim, Xcelium: You have to import pkg or
`include file in top testbench
VCS: VCS automatically search testcase in other Compilation
Units
UVM_WARNING @ 0: reporter [BDTYP] Cannot create a component of type 'my_test' because it is not registered with the factory. UVM_FATAL @ 0: reporter [INVTST] Requested test from command line +UVM_TESTNAME=my_test not found. UVM_INFO /home/EDA/Cadence/XCELIUM2109/tools/methodology/UVM/CDNS-1.2/sv/src/base/uvm_report_catcher.svh(705) @ 0: reporter [UVM/REPORT/CATCHER]
QuestaSim log:
# UVM_INFO verilog_src/questa_uvm_pkg-1.2/src/questa_uvm_pkg.sv(277) @ 0: reporter [Questa UVM] QUESTA_UVM-1.2.3# UVM_INFO verilog_src/questa_uvm_pkg-1.2/src/questa_uvm_pkg.sv(278) @ 0: reporter [Questa UVM] questa_uvm::init(+struct)# UVM_WARNING @ 0: reporter [BDTYP] Cannot create a component of type 'my_test' because it is not registered with the factory.# UVM_FATAL @ 0: reporter [INVTST] Requested test from command line +UVM_TESTNAME=my_test not found.# UVM_INFO verilog_src/uvm-1.2/src/base/uvm_report_server.svh(847) @ 0: reporter [UVM/REPORT/SERVER]
solution:
uncomment //import sim_pkg::*; in tb_top.sv
Efficient Sequence
Objection in UVM
Objections are handled in pre/post body decalared in
a base sequence class
This is efficient for all sequence execution options:
Default sequences use body objections
Test sequences use test objections
Subsequences use objections of the root sequence which calls
them
A default sequence is a root sequence, so the pre/post
body methods are executed and objection are raised/dropped
there
Test sequence:
A test sequence is a root sequence, so the pre/post
body methods are executed. However, for a test sequence,
starting_phase is null and so the objection is
not handled in the sequence. The test must raise and drop objections
Subsequence:
Not a root sequence, so pre/post body methods are
not executed. The root sequence which ultimately called the subsequence
handles the objections, using one of the two options above.
If a sequence is call via a `uvm_do
variant, the it is defined as a subsequence and its
pre/post_body() methods are not executed.
objection change in UVM1.2
Raising or dropping objections directly from
starting_phase is deprecated
-lca: Enables Limited Customer Availability feature,
which is not fully test
+vpi: Enables the use of VPI PLI access
routines.
Verilog PLI (Programming Language Interface) is a mechanism to
invoke C or C++ functions from Verilog code.
-P <pli.tab>: Specifies a PLI table file
${VERDI_HOME}/share/PLI/VCS/LINUX64/novas.tb
+define+=: Define a text macro,
Test for this definition in your Verilog source code using the
`ifdef compiler directive
+define+SIMULATION when compiling
`ifdef SIMULATOIN in code
-debug_access: Enables dumping to FSDB/VPD, and
limited read/callback capability. Use -debug_access+classs
for testbench debug, and debug_access+all for all debug
capabilities. Refer the VCS user guide for more granular options for
debug control under the switch debug_access and refer to
debug_region for region control
-y : Specifies a Verilog library
directory to search for module definitons
-v <filename>: Specifies a Verilog library
file to search for module definitons
+nospecify: Suppresses module path delays and time
checks in specify blocks
-l <filename>: (lower case L) Specifies a log
file where VCS records compilation message and runtime messages if you
include the -R, -RI, or -RIG option
+vcs+fsdbon: A compile-time
substitute for $fsdbDumpvars system task. The
+vcs+fsdbon switch enables dumping for the entire
design. If you do not add a corresponding
-debug_access* switch, then -debug_access is
automatically added. Note that you must also set
VERDI_HOME.
$ ./simv
FSDB Dumper for VCS, Release Verdi_S-2021.09-SP2-2, Linux
x86_64/64bit, 05/22/2022 (C) 1996 - 2022 by Synopsys, Inc. *Verdi* :
Create FSDB file 'novas.fsdb' *Verdi* : Begin traversing the scopes,
layer (0). *Verdi* : End of traversing.
+vcs+vcdpluson: A compile-time
substitute for $vcdpluson system task. The
+vcs+vcdpluson switch enables dumping for the entire
design. If you do not add a corresponding
-debug_access* switch, then -debug_access is
automatically added
$ ./simv
VCD+ Writer S-2021.09-SP2-2_Full64 Copyright (c) 1991-2021 by
Synopsys Inc.
+incdir+<directory>: Specifies the directories
that contain the files you specified with the `include
compiler directive. You can specify more than on directory, separating
each path name with the + character.
Compile time Use Model
Just add the -kdb option to VCS executables when running
simulation
Three steps flow:
vlogan/vhdlan/syscan -kdb
Compile design and generate un-resolved KDB to
./work
vcs -kdb -debug_access+all <other option>
Generate elaborated KDB to ./sim.dadir
Two steps flow:
vcs -kdb -debug_access+all <other option>
Compile design and generate elaborated KDB to
./simv.dadir
Common simv Option
-gv <gen=value>: override runtime VHDL generics
*
-ucli: stop at Tcl prompt upon start-up
-i <run.tcl>: execute specified Tcl script upon
start-up
-l <logfile>: create runtime logfile
-gui: create runtime logfile
-xlrm: allow relaxed/non-LRM compliant code
-cm <options>: enable coverate options
verdi binkey
SHIFT+A: Find Signal/Find Instance/Find
Instport
SHIFT+S: Find Scope
module traverse
Show Calling
Show Definition
Double-Click instance name is same with click
Show Definition
Double-Click module name is same with click Show
Calling
signal traverse
Driver
Load
Double-Click signal name is same with click
Driver
-simBin <simv_executable>: Specify the path of the
simulation binary file.
-dbdir: Specify the daidir (simv.daidir ) directory to
load
In the VCS two-step flow, the VCS generated KDB (kdb.elab++) is saved
under the simv.daidir/ directory (like
simv.daidir/kdb.elab++).
-f file_name / -file file_name: Load an ASCII file
containing design source files and additional simulator options
Import Design from UFE
Knowledge Database (KDB): As it compiles the design,
the Verdi platform uses its internal synthesis technology to recognize
and extract specific structural, logical, and functional information
about the design and stores the resulting detailed design information in
the KDB
The Unified Compiler Flow (UFE) uses VCS with the -kdb
option and the generated simv.daidar includes the
KDB information
verdi -dbdir simv.daidir
Use the new -dbdir option to specify the simv.daidir
directory
verdi -simBin simv
Load simv.daidir from the same
directory as simv and invoke Verdi if
simv.daidir is available
verdi -ssf novas.fsdb
Load KDB automatically from FSDB,
For 2 and 3, use the -dbdir option to load
simv.dadir if you have move it to somewhere else
module load vcs
module load verdi
both vcs and verdi are needed for design import
Reference Design
and FSDB on the Command Line
1
verdi -f <source_file_name> -ssf <fsdb_file_name>
Where, source_file_name is the source file name and fsdb_file_name is
the name of the FSDB file
include("path/to/MyModule.jl") using .MyModule # !!! don't work in Pluto
struct0 = Mystruct()
activate a Julia environment and execute a file using the
command line
1
julia --project=. your_script.jl
The --project=. argument tells Julia to look for a
Project.toml and Manifest.toml file in the
current directory (indicated by .)
Sharing Project Environments
instantiate command to download and install all packages
and their dependencies listed in Project.toml (and
Manifest.toml if present)
Feature / Command
activate
generate
resolve
instantiate
Primary Goal
Switch to a specific project folder's
context.
Create a brand new project skeleton from
scratch.
Recalculate the dependency tree for the
current Julia version.
Download and install the specific versions
listed in the Manifest.
Julia Version Role
Does not check version; just points Julia
to a directory.
Creates a Project.toml
compatible with the running Julia version.
Crucial: Filters package
versions based on the [compat] julia field.
Uses the Julia version to ensure the
Manifest is valid before downloading.
Manifest Impact
None.
None (a manifest is only created once you
add packages).
Rewrites the
Manifest.toml to match the current Julia environment.
Follows the existing
Manifest.toml to recreate the environment.
Cross-Version Use
Same command works across all Julia
versions.
Standard way to start a project regardless
of Julia version.
Used to "fix" a Manifest when moving a
project to a newer/older Julia version.
Used to "build" the project once
resolve has created a valid Manifest.
Error Handling
Rarely fails (unless the path doesn't
exist).
Fails if the directory name is invalid or
already exists.
Fails if no package versions support your
running Julia version.
Fails if the Manifest was built for a
different Julia version (pre-1.11).
Basics
parentmodule: determine the package a function in Julia
originates from
names: Get a vector of the public names of a Module,
excluding deprecated names
undef: undef is a special marker used when constructing
arrays (including vectors) to indicate that the elements of the array
should not be initialized to any specific value.
collect: return an Array of all items in a collection or
iterator, collect(2:5), collect('B':'D'),
collect("HELLO")
!: a function naming convention to indicate that a
function mutates its arguments in place, meaning the changes will be
visible outside the function. When a function is designed to modify its
arguments, it is good practice to append a ! (exclamation
mark) to its name
eltype: To find the type of the elements that are
iterated over in a collection
typeof: To determine the specific type of any given
value
Any: It is used to construct a heterogeneous array that
can hold elements of any type, like
Any[1, "hello", 3.14]
^: Repeat a regex n times (s^n
is same with repeat(s, n)); Exponentiation operator
parse: convert a text string to anything else.
parse(Int, "42"), parse(Float64, "42")
String * : concatenate strings,
"The " * engine *
String $: string interpolation, use
$(variable) instead of $variable when there is
no whitespace that can clearly distinguish the variable name from the
surrounding text
vec: Reshape the array as a one-dimensional column
vector
A named tuple only allows you to use symbols as keys
All types of tuples are immutable, meaning you cannot change
them
implicit naming from identifiers
1 2 3
x = 0 t = (; x) # t is (x = 0,) u = (; t.x) # u is (x = 0,)
composite type (struct) &
type annotation
:: is used to annotate variables and expressions with
their type. x::T means variable x should have
type T. It helps Julia figure out how many bytes are needed
to hold all fields in a struct
1 2 3 4 5
struct Archer name::String health::Int arrows::Int end
closure
varargs
"varargs" (variable arguments) refers to the ability of a function to
accept an arbitrary number of arguments. This is achieved using the
splat operator (...) in the function
definition.
1 2 3 4 5 6 7
function my_sum(a, b, rest...) total = a + b for x in rest total += x end return total end
1
my_sum(1, 2, 3, 4, 5) # 15
keyword arguments
a semicolon (;) separates positional arguments
from keyword arguments in the function signature. All arguments to the
right of the semicolon are treated as keyword arguments. They can
optionally have default values
views
A view is essentially a
pointer to a sub-section of another vector,
but not a standalone vector itself
@views is a macro that converts sliced arrays into views
(pointers are much cheaper than creating copies of arrays). For more
information on how to use the view syntax correctly
semicolon after steprange
placing a semicolon ; after a step range expression
inside square brackets, e.g., [1:10;], changes the
resulting object from a UnitRange to a
Vector
1 2 3 4 5
b = [1:2:10] # Vector{StepRange{Int64, Int64}} a = [1:2:10;] # Vector{Int64}
size(b) # (1) size(a) # (5)
element-wise operations
Dot syntax for operators: For binary operators like
+, -, *, /,
^
Dot syntax for functions: For functions, the dot is placed
after the function name.
Property destructuring
1 2 3 4 5 6 7 8
julia> (; b, a) = (a=1, b=2, c=3) (a = 1, b = 2, c = 3)
julia> a 1
julia> b 2
One-line functions
"one-line function" also known as the compact
"assignment form"
1
function_name(parameters) = expression
Anonymous Functions (Lambda Functions)
functions without a name (parameters) -> expression,
often defined inline for use with higher-order functions like
map, filter, or reduce
1 2
numbers = [1, 2, 3] doubled_numbers = map(x -> 2 * x, numbers) # doubled_numbers will be [2, 4, 6]
do keyword is syntactic sugar for
creating an anonymous function and passing it as the
first argument to another function
1 2 3 4
map([1, 2, 3]) do x y = x * 2 return y + 1 end
do starts the block.
x, y (optional) following do are the
arguments the anonymous function receives.
end closes the block
CircularBuffer
Feature
Vector (Standard)
CircularBuffer
(DataStructures.jl)
Push/Pop Front
\(O(n)\)
(Shifts all elements)
\(O(1)\)
(Updates head pointer)
Push/Pop Back
\(O(1)\)
(Amortized)
\(O(1)\)
Random Access
\(O(1)\)
(Direct)
\(O(1)\)
(With index wrapping logic)
Capacity
Dynamic: Grows as
needed
Fixed: Initialized at set
size
Overflow
Reallocates memory
Overwrites the oldest
data
Memory Layout
Contiguous
Contiguous (internally wraps)
Best Use Case
General collections / Appending
Sliding windows / Real-time buffers
1 2 3 4 5 6 7 8 9 10 11 12
using DataStructures
# Initialize a CircularBuffer of type Int with capacity 3 cb = CircularBuffer{Int}(3)
# Add elements push!(cb, 1) # [1] push!(cb, 2) # [1, 2] append!(cb, [3, 4]) # [2, 3, 4] (1 is overwritten because capacity is 3)
# Add to the front pushfirst!(cb, 0) # [0, 2, 3] (4 is overwritten)
push!(cb, item): Adds a single item to
the back of the buffer. If the buffer is at its capacity, the item at
the front (the oldest) is removed to make room.
append!(cb, collection): Adds multiple
items from another collection to the back of the buffer. This is
essentially a shorthand for calling push! on each element
of the collection.
Feature
push!
append!
Input
A single item
A collection of
items
Action
Adds one element as a single entry
Unpacks all elements from the input
using vs
import
that’s the difference between using and
import - the former brings all exported names into scope,
while the latter only brings NiceStuff (the module identifier) into
scope.
Since the discrete Fourier Transform of real input is
Hermitian-symmetric, the negative frequency terms are
taken to be the complex conjugates of the corresponding positive
frequency terms
scipy.signal.residue: (H(s) = )
Converts numerator/denominator arrays into residues, poles, and a direct
polynomial
scipy.signal.invres: (H(s) ) Converts
residues, poles, and a direct polynomial back into numerator/denominator
arrays
defmake_ctle(rx_bw: float, peak_freq: float, peak_mag: float, w: Rvec) -> tuple[Rvec, Cvec]: # pylint: disable=too-many-arguments # noqa: F405 """ Generate the frequency response of a continuous time linear equalizer (CTLE), given the: - signal path bandwidth, - peaking specification, and - list of frequencies of interest. Args: rx_bw: The natural (or, unequalized) signal path bandwidth (Hz). peak_freq: The location of the desired peak in the frequency response (Hz). peak_mag: The desired relative magnitude of the peak (dB). w: The list of frequencies of interest (rads./s). - The zero location is chosen, so as to provide the desired degree of peaking. """
p2 = -2.0 * pi * rx_bw p1 = -2.0 * pi * peak_freq z = p1 / pow(10.0, peak_mag / 20.0) if p2 != p1: r1 = (z - p1) / (p2 - p1) r2 = 1 - r1 else: r1 = -1.0 r2 = z - p1 b, a = invres([r1, r2], [p1, p2], []) w, H = freqs(b, a, w) H /= max(abs(H))
return (w, H)
np.where
There are actually two distinct call signatures:
Call
Returns
Use
np.where(cond, a, b)
array, a/b chosen element-wise
select values
np.where(cond)
tuple of index arrays where cond is
True
find positions
Matlab
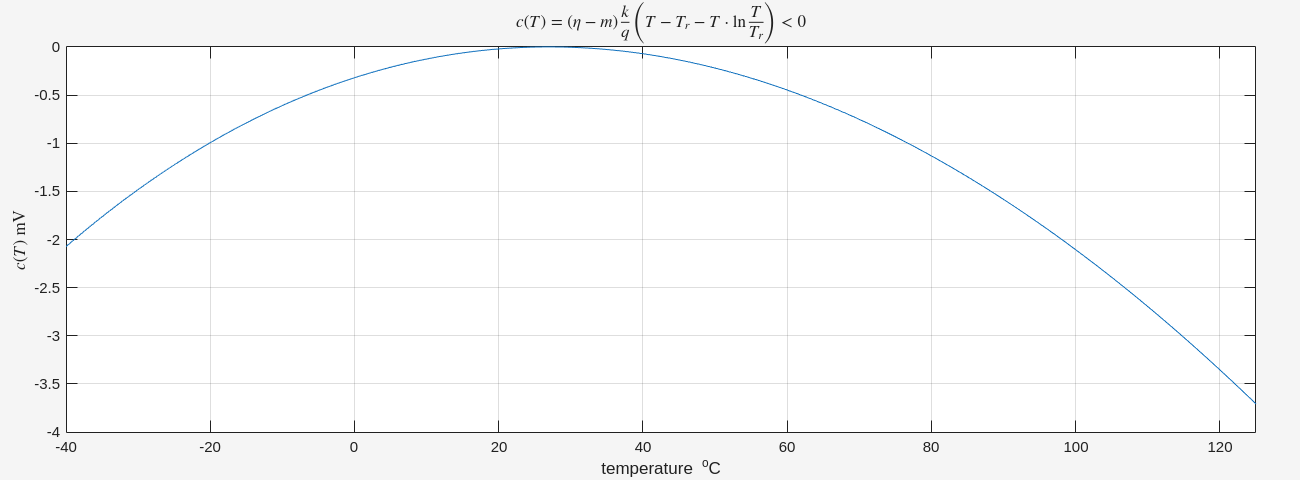
LaTeX code for the expression
1 2 3
title('$c(T) = (\eta - m) \frac{k}{q} \left( T - T_r - T \cdot \ln \frac{T}{T_r} \right) < 0$', 'Interpreter', 'latex');
ylabel('$c(T)$ mV', 'Interpreter', 'latex');
Dollar Signs ($): Wrapping the equation
in $...$ tells the LaTeX engine to use "inline math mode,"
which ensures proper spacing and formatting for symbols.
Interpreter: Adding
'Interpreter', 'latex' at the end is the "switch" that
tells MATLAB not to use its basic text engine.
identify class of an object or variable
1 2 3
x = 42; type_name = class(x); % Returns 'double' disp(type_name)
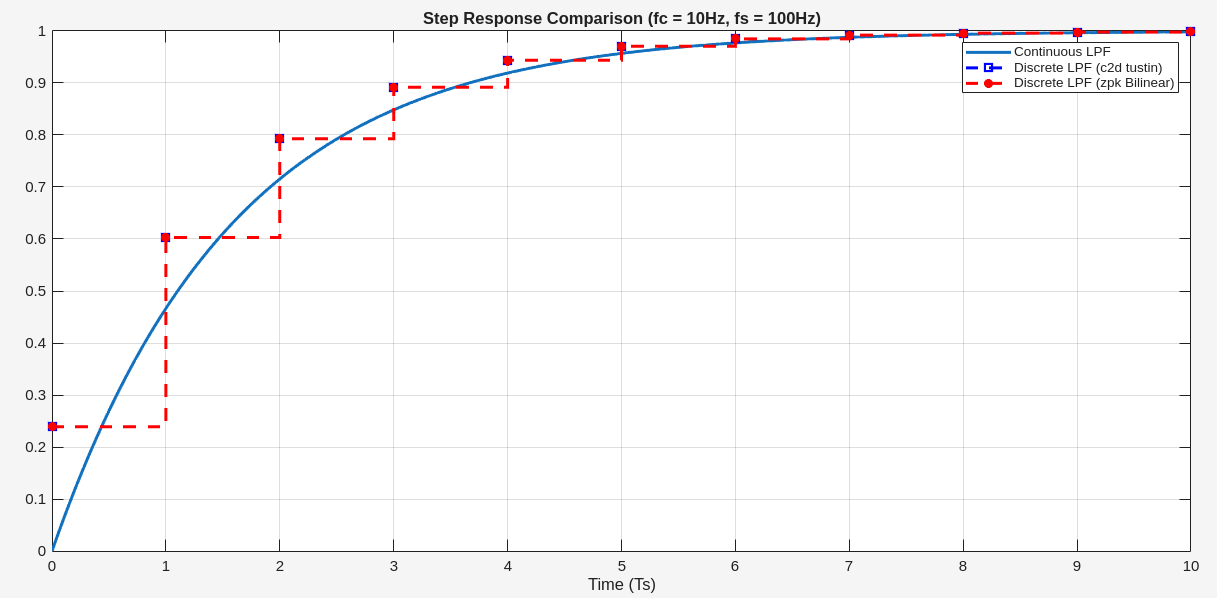
zpk
Use zpk to create zero-pole-gain models
sys = zpk(zeros,poles,gain) creates a
continuous-time zero-pole-gain model with zeros and
poles specified as vectors and the scalar value of gain.
sys = zpk(zeros,poles,gain,ts) creates a
discrete-time zero-pole-gain model with sample time ts.
Set ts to -1 or [] to leave the
sample time unspecified.
zpkdata
Access zero-pole-gain data
1
[z,p,k] = zpkdata(sys,'v')
the sampling time associated with that ZPK data
1
Ts = sys_d.Ts; % Returns the sampling interval (1/fs)
% 1. Define Continuous ZPK Model fc = 10; % Cutoff frequency in Hz wc = 2 * pi * fc; % Cutoff frequency in rad/s
z = []; % No zeros p = -wc; % Single pole at -wc k = wc; % Gain (to ensure DC gain = 1)
sys_c = zpk(z, p, k);
% 2. Convert to Discrete via Bilinear Transformation fs = 100; % Sampling frequency in Hz dt = 1/fs;
% 'tustin' flag is the standard name for the bilinear transformation in control theory sys_d = c2d(sys_c, dt, 'tustin'); % 'tustin' is the Bilinear method in MATLAB
% Extract zeros, poles, and gain from sys_c [zc, pc, kc] = zpkdata(sys_c, 'v'); [zd, pd, kd] = bilinear(zc, pc, kc, fs); sys_dbli = zpk(zd, pd, kd, dt);
By using NaN, the surf command will simply
not render any polygons over the invalid coordinates. Your 3D plot will
sharply truncate exactly at the physical layout boundary rule line
(\(nsab = nsodab\))
Simulink
Quick Insert menu
Single-click anywhere on the empty white space of
your model canvas.
Type the name of the block you want (e.g., "Gain",
"Scope", or "Triggered Subsystem")
Sequential Execution: If multiple actions are assigned to a
single event (e.g., WhenEvent[cond, {action1, action2}]),
they are evaluated in order.
DiscreteVariables in NDSolve: handle state
variables that only change at specific, discontinuous moments rather
than changing continuously with the independent variable (usually time
\(t\)), solution returned will be a
piecewise constant
Markdown
> [!NOTE]: General useful
information
[!NOTE]
> [!IMPORTANT]: Crucial information
for user success
[!IMPORTANT]
> [!WARNING]: Urgent information to
avoid potential problems
[!WARNING]
> [!TIP]: Helpful advice or better
ways to do things
[!TIP]
> [!CAUTION]: Negative consequences
or risks of certain actions
[!CAUTION]
Latex
In math mode, LaTeX provides several commands to insert horizontal
space of specific widths:
Command
Width
Name
\,
3/18 em
thin space
\:
4/18 em
medium space
\;
5/18 em
thick space
\!
−3/18 em
negative thin space
\quad
1 em
quad
\qquad
2 em
double quad
\operatorname{...} — math operator in
an upright (roman) font with appropriate mathematical spacing \[
\operatorname{sinc}(x)
\]
mermaid
Mermaid is a JavaScript based diagramming and charting tool
that takes Markdown-inspired text definitions and creates diagrams
dynamically in the browser
graph TD;A-->B;A-->C;B-->D;C-->D;
C++
Using g++ only
conditional.cpp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
#include<iostream>
#define na 4
intmain(){ int a[na];
a[0] = 2; for (int n = 1; n < na; n++) a[n] = a[n-1] + 1;
#ifdef DEBUG // Only kept by preprocessor if DEBUG defined for (int n = 0; n < na; n++) { std::cout << "a[" << n << "] = " << a[n] << std::endl; } #endif return0; }
Before inserting sign-off metal fill, stream out a GDSII stream file
of the current database. Specify the mapping file and units that match
with the rule deck you specify while inserting metal fill. If necessary,
include the detailed-cell (-merge option) Graphic Database
System (GDS).
Just replace run_pvs_metal_fill with
run_pegasus_metal_fill
Note: Innovus metal fill (e.g.
addMetalFill, addViaFill, etc.) does not
support 20nm and below node design rules. We strongly recommend the
Pegasus/PVS metal fill solution for 20nm and below. If you have sign-off
metal fill rule deck for 28nm and above available, we recommend you to
move to Pegasus/PVS solution too.
trimMetalFillNearNet does not check DRC rules. It
only removes the metal fill with specified spacing
Do not perform ECO operations after dump in
sign-off metal fill (by run_pvs_metal_fill or
run_pegasus_metal_fill), especially, at 20nm and below
nodes.
If you perform an ECO action, the tool cannot get DRC clean
because trimMetalFill does not support 20nm and below node
design rules.
The sign-off metal fill typically does not cause DRC issues with
regular wires.
The run_pvs_metal_fill command does the following:
Runs PVS with the fill rules to create a GDSII output file.
Converts the GDSII to a DEF format file based on the GDSII to DEF
layermap provided.
Loads the resulting DEF file into Innovus.
Pegasus is similar to PVS, shown as below,
The run_pegasus_metal_fill command does the
following:
Runs Pegasus with the fill rules to create a GDSII output file.
Converts the GDSII to a DEF format file based on the GDSII to DEF
layermap provided.
Loads the resulting DEF file into Innovus.
Reference:
Innovus User Guide, Product Version 21.12, Last Updated in November
2021
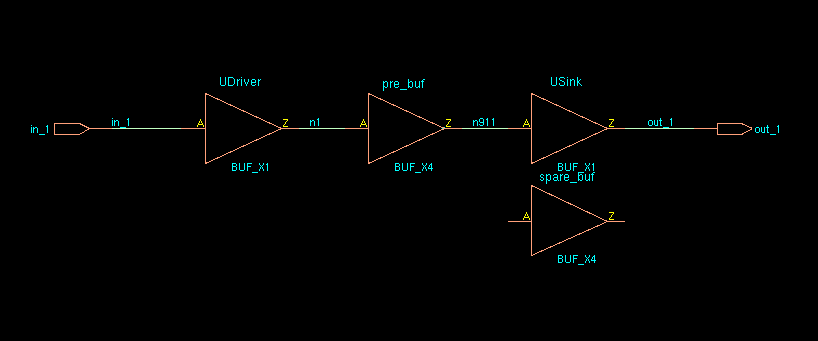
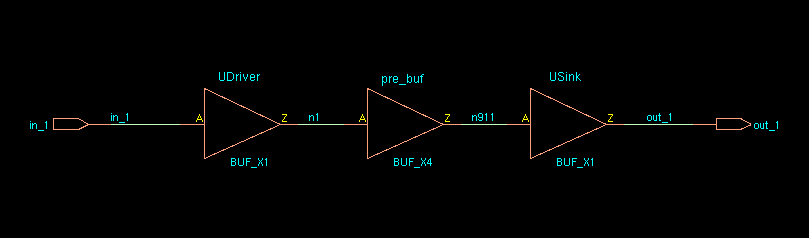
How
does EDI System identify spare cells in a post-mask ECO flow?
How
does EDI System identify spare cells in a post-mask ECO flow?
Spare cells should have a unique string in their instance name to
identify them. Then the command specifySpareGate or
ecoDesign -useSpareCells patternName is run to identify the
spare instances. For example, if all spare cells have _spare_ in their
name then they are identified using:
1
specifySpareGate -inst *_spare_*
OR
1
ecoDesign -spareCells *_spare_* ...
Note: if you are making manual ECO
changes to a netlist and converting a spare cell to a logical instance,
it's important to change the instance name. Otherwise,
the instance may be identified as a spare cell if a future ECO is
performed because it still has the spare cell instance name.
Note: sparecell's pointer and name is swapped with
the placed cell.
Error in "Innovus
Text Command Reference 21.12"
ecoSwapSpareCell
If the cell to be swapped is unplaced, it is mapped to the spare
cell. *instName* is deleted, and its connection is
transferred to the spare cell. If the cell to be swapped is placed, it
is swapped with the spare cell and is renamed to
*instNameSuffix* if the -suffix option is
used. If a suffix is not specified, the *instName* cell is
renamed to *spareCellInstName*. The *instName*
cell's connections are transferred to *spareCellInstName*.
The input of *instName* is tielo, based on the
global connection definition.
In Visio, open the file you want to appear in the Word
document.
Make sure nothing is selected, and then, on the Home
tab, select Copy or press Ctrl+C
paste
In Word, select where you want the Visio drawing to
appear and then select Paste or press
Ctrl+V
In PowerPoint or Excel, On the Home
tab, select Paste > Paste Special, and then select
Microsoft Visio Drawing Object
LSF (Platform Load Sharing
Facility)
bjobs: Displaying Job Status
bkill: cancels pending batch jobs and sends signals to
running jobs
bhosts: displays hosts and their static and dynamic
resources
busers: displays information about the user who runs the
command
Module System
module avail: Lists the modules currently available to
load on the system
module list: Lists the modules currently loaded in the
user environment.
module load|add: This loads the
requested module into the active environment
module purge: To clear all modules
module rm|unload: To unload a
module
module switch|swap: To change the version of a loaded
software module
unlock "secured"
(read-protected) PDF
1 2 3 4 5 6 7 8
# Source - https://stackoverflow.com/a/63422342 # Posted by Satish Dubey, modified by community. See post 'Timeline' for change history # Retrieved 2026-01-05, License - CC BY-SA 4.0
import pikepdf
pdf = pikepdf.open('filepath', allow_overwriting_input=True) pdf.save('filepath')
MATLAB
Win10 Unable to open the requested feature. Error code: -202
clear AppData\Roaming\MathWorks\MATLAB
miniconda3/envs/myenv/bin/../lib/libstdc++.so.6:
version `GLIBCXX_3.4.32' not found
$ sudo lvdisplay --- Logical volume --- LV Path /dev/rl/swap LV Name swap VG Name rl LV UUID toZKEu-P5oV-6WOV-026Z-eFnI-xaSP-FgEbz5 LV Write Access read/write LV Creation host, time myserver, 2021-12-03 21:28:03 +0800 LV Status available # open 2 LV Size 5.00 GiB Current LE 1280 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 8192 Block device 253:1
--- Logical volume --- LV Path /dev/rl/root LV Name root VG Name rl LV UUID S2soRE-umc7-Z6b3-i44x-TiBO-ulnk-ETgEoj LV Write Access read/write LV Creation host, time myserver, 2021-12-03 21:28:03 +0800 LV Status available # open 1 LV Size <194.00 GiB Current LE 49663 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 8192 Block device 253:0
compile vim from
source with GUI support
1 2 3 4
# gtk3 in Rocky Linux 8.5 ./configure --with-features=huge --enable-gui=gtk3 --enable-python3interp --prefix=/usr make -j`nproc` sudo make install
binkey
Inserting a new line below: o
above: O
To insert before the cursor: i
After: a
Before the line (home): I
Append at the end of line: A
network connection using
nmcli
Problem
There is no network connection and device is not managed
1 2 3 4
$ nmcli device status DEVICE TYPE STATE CONNECTION eth0 ethernet unmanaged -- lo loopback unmanaged --
solution
1
sudo nmcli networking on
Then, eth0 is connected
1 2 3 4
$ nmcli device status DEVICE TYPE STATE CONNECTION eth0 ethernet connected Ethernet connection 1 lo loopback unmanaged --
What
is the proper method to remove old kernels from a Red Hat Enterprise
Linux system?
Red Hat Enterprise Linux 8
The YUM version 4 (based on the upstream DNF project)
method for removing kernels and keeping only the latest version and
running kernel:
1
$ yum remove --oldinstallonly
From the yum man page:
1 2 3
dnf [options] remove --oldinstallonly Removes old installonly packages, keeping only latest versions and version of running kernel.
New
windows and forms appear behind the Library Manager in background when
using GNOME 3
Using Red Hat Enterprise Linux 8, Rocky
Linux 8 and the GNOME 3 window manager, the
new Virtuoso Schematic/Layout/ADE windows and forms sometimes pop up
under or below the Library Manager or on the desktop in
the background instead of the foreground and cannot be seen. Sometimes,
they are iconized; they do not come on the top in front, though it is
the most recent window opened.
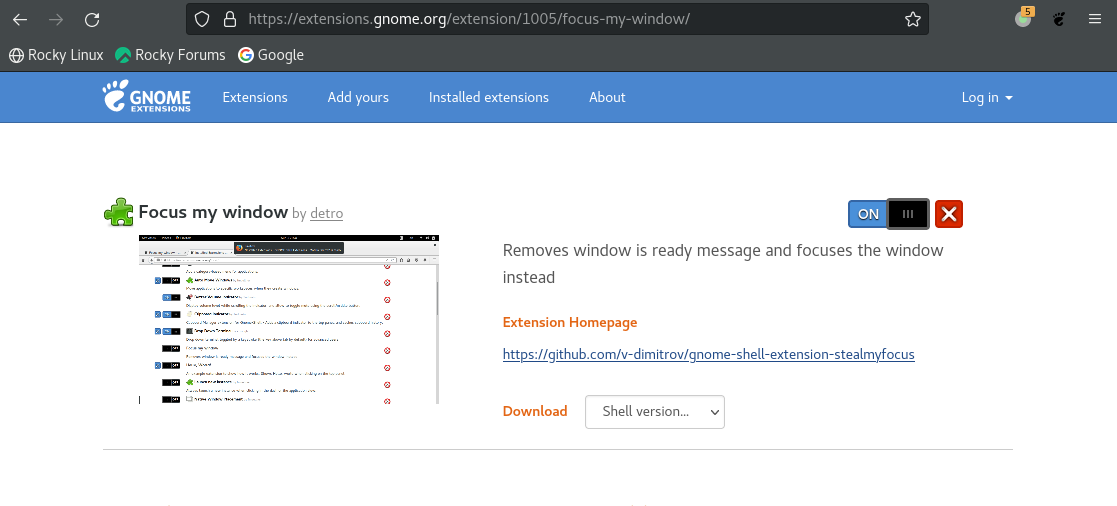
solution
Install Focus my window GNOME Shell extension
reference
Article (11612426) Title: New windows and forms appear behind the
Library Manager in background or iconized instead of foreground on RHEL
and SuSE Linux in GNOME, KDE Desktop, Metacity window manager
I mean Negative Capability, that is when a man is capable of being in uncertainties, Mysteries, doubts, without any irritable reaching after fact and reason
Self-pity gets pretty close to paranoia and paranoia is one of the very hardest things to reverse. It's a ridiculous way to behave and when you avoid it you get a great advantage over everybody else, almost everybody else, because self-pity is a standard condition and yet you can train yourself out of it.
Envy is a really stupid sin because it's the only one you could never possibly have any fun at. There's a lot of pain and no fun. Why would you want to get on that trolley?
— Charlie Munger
1 2 3 4
Every mischance in life was an opportunity to learn something and your duty was not to be submerged in self-pity, but to utilize the terrible blow in a constructive fashion.
Carson's prescriptions for sure misery included: 1) Ingesting chemicals in an effort to alter mood or perception; 2) Envy; and 3) Resentment.
Johnson spoke well when he said that life is hard enough to swallow without squeezing in the bitter rind of resentment.
1 2 3 4
The past was a lie, that memory has no return, that every spring gone by could never be recovered, and that the wildest and most tenacious love was an ephemeral truth in the end.
- Gabriel García Márquez's One Hundred Years of Solitude
1 2 3
Life can only be understood backwards; but it must be lived forwards.
— Soren Kierkegaard
1 2 3 4 5
我有一种哲学,就是不为过去所做的事情后悔。只是设法记住你当时为什么做出那样的决定。
I have a philosophy that it doesn't do any good to go and make regrets about what you did before but to try to remember how you made the decision at the time.
— Richard P. Feynman, Perfectly Reasonable Deviations from the Beaten Track, p. 421
1 2 3 4 5 6 7 8 9
The healthier strategy for controlling the fear of failure is to redefine the meaning of your mistakes.
People with low self-esteem consider mistakes to be an indication of a general lack of worth. Each error reaffirms their underlying belief that something is terribly wrong with them.
In chapter 10, on handling mistakes, you will explore one of the fundamental laws of human nature: that you always choose actions that seem most likely to meet your needs based on current awareness. You make the best decision you can at any point in time, given what you know and what you want.
The secret to coping with any failure is to recognize that each decision you've made was the very best one available under the circumstances.